How to Detect Duplicates
Overview
The Duplicates Detection stage uses the configured input metadata to calculate the document hash and tries to find the closest matching document based on the Jaccard similarity index.
-
The document hash is compared to other pre-existing clusters and if a match greater than the specified threshold is found then the GUID of the cluster with the highest similarity is returned as metadata.
-
If no match is found then the document hash is added to the database and will be used in future comparisons.
-
In this case the output property is the GUID of the newly added cluster.
-
The Duplicates Detection stage only handles comparisons, not text extractions.
-
Additional stages might need to be used to extract the information we want to compare.
How to Add the Duplicates Detection Component
Procedure:
-
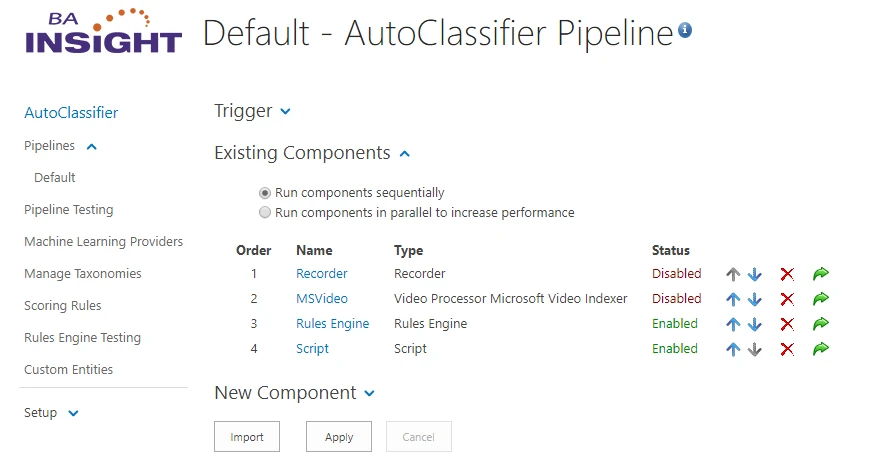
Navigate to the AutoClassifier Pipelines component page.
-
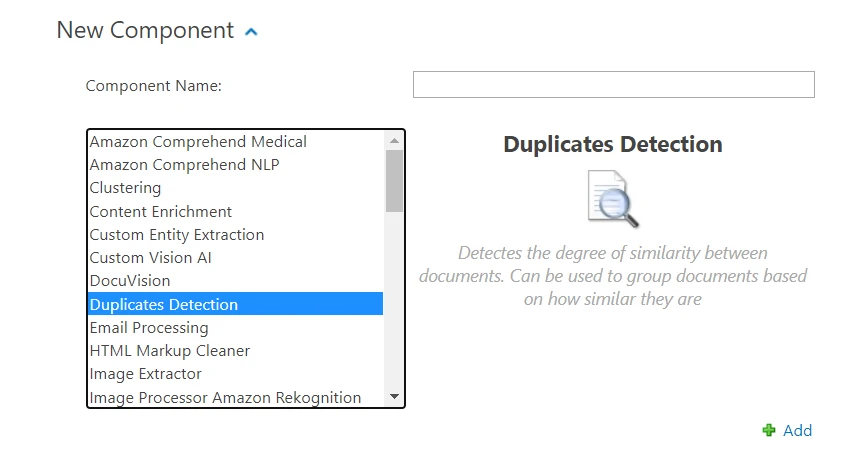
Click New Component and select Duplicates Detection from the component list:
-
Name your new component, and click the Add button the in lower right corner.
-
Click Apply to save your changes.
-
The Duplicates Detection component will be added to your Existing Components list.
How to Configure the Duplicates Detection Component
-
Similarity Detection Property
-
Name of the metadata value to be used for Duplicates Detection
-
Default: body
-
-
Similarity threshold(%)
-
Percentage of similarity for the cluster to be declared a duplicate
-
-
Delete All Clusters from Database
-
Delete all Cluster IDs from the database
-
Output Properties
| Property | Type | Multivalue | Description |
|---|---|---|---|
| DuplicateDetectionClusterGuid | GUID | No | The id of the closest duplicate cluster |