How to Extract Data from Raw Binary Files
Tika Extractor Component
Use the Tika Extractor component to extract body and metadata from raw binary files.
Use this component when calls to the source system are unable to extract the body and metadata but classification requires this data.
- Add the component.
- Optionally, you can reset the partition size.
- To perform the reset, go to Configuration > Profiling > Binary Data Extraction:
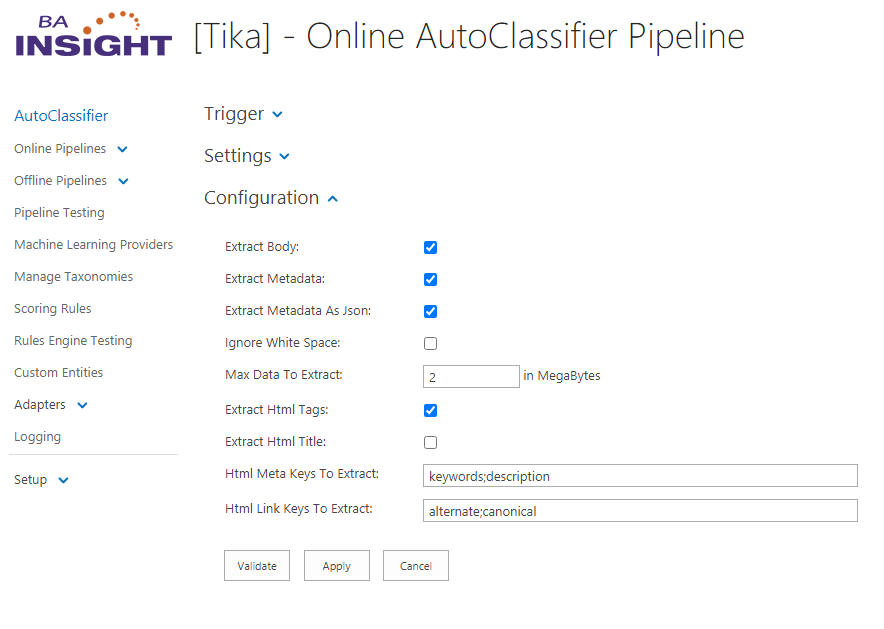
- To perform the reset, go to Configuration > Profiling > Binary Data Extraction:
- Existing Components: Click the named link for this component to see the Configuration section.
- Extract Body: Click to extract the body from raw binary files required for classification.
- Extract Metadata: Click to extract the metadata from raw binary files required for classification.
- Ignore White Space: Click to ignore white space characters and to output the body/metadata contents without any white space separators.
- Max Data to Extract: If there is no limitation, leave blank. Alternatively, enter the maximum amount of data in MBs.
- Output Properties: DependS on the configuration.
- Extract Html Tags: Check to Enable HTML Tag Extraction
- Extract Html Title: Check to extract HTML Title when available
- Html Meta Keys to Extract: (default: keywords;description)
- "*" can also be used to extract all meta tags to determine which tags are available
- "*" can also be used to extract all meta tags to determine which tags are available
- Html Link Keys to Extract: (default: alternate;canonical)
- "*" can also be used to extract all link tags to determine which tags are available
Note: The extracted metadata by this component is the metadata that belongs to the document itself as in the example below for the PDF.
To be able to detect all extracted metadata by this component, you can use Pipeline Testing page or you can check the DEBUG logs and look for metadata names prefixed with "Tika" as in the image below.
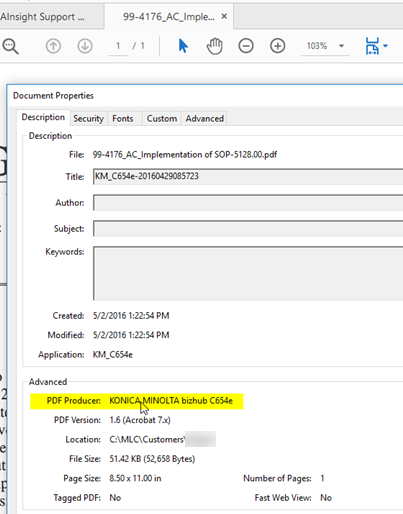
Example of extracted metadata visible in Pipeline Testing:

Trigger Script
The Tika stage does not extract raw data from image and video files.
A trigger script is used to help identify the file extension and determine if Tika is skipped when processing.
Log.Debug("Tika trigger called");
var blockedExtensions = new List<string>() { "jpg", "jpeg", "png", "gif", "tiff", "psd", "ai", "mp4", "avi", "mov", "mpeg", "mpeg4" };
var propertiesWithExtensions = new List<string>() { "FileExtension", "OriginalPath", "FileName", "Url", "escbase_fileextension" };
string customExtensionProperty = "";
string fileExtension = string.Empty;
if (string.IsNullOrEmpty(customExtensionProperty)){
foreach(var extensionProperty in propertiesWithExtensions){
string extractedExtension = null;
extractedExtension = item.Get<string>(extensionProperty);
if (!string.IsNullOrEmpty(extractedExtension))
{
fileExtension = extensionProperty.Equals("FileExtension",
StringComparison.InvariantCultureIgnoreCase)
? extractedExtension
: Path.GetExtension(extractedExtension).Trim('.');
break;
}
}
}
else
fileExtension = item.Get<string>(customExtensionProperty);
Log.Debug("Extracted File extension: "+fileExtension);
if(!string.IsNullOrEmpty(fileExtension) && blockedExtensions.Contains(fileExtension)){
Log.Debug("Detected file extension to be skipped");
return false;
}
return true;Script Parameters
- blockedExtensions
- A list of image and video extensions that the Tika stage will not process.
- To add a new extension to the list, write the extension name between quotes.
- propertiesWithExtensions
- A list of properties that include document extensions.
- For example, the AutoClassifier Annotator returns the file extension in the FileExtension property, Connectivity Hub uses the escbase_fileextension property.
- customExtensionProperty
- If the file extension is returned in a custom property replace "" with "*yourCustomPropertyName*"