How to Extract Languages
The Language Detector pipeline stage detects all languages in a specific processed multi-lingual metadata (for example document body) using the NTextCat library.
How to Add the Language Detector to AutoClassifier
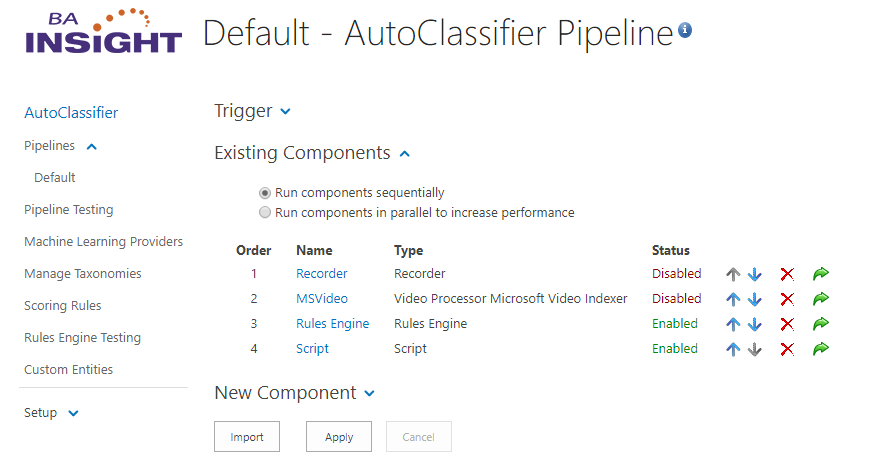
- Navigate to the AutoClassifier Pipelines component page.
-
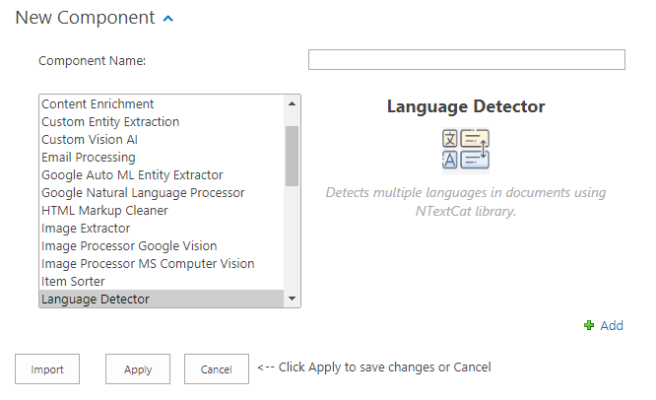
Click New Component and select Language Detector from the component list:
-
Name your new Language Detector component and click Add

-
Click Apply to save your changes.
-
Ensure your new Language Detector component is placed in the list of existing pipeline stages.

How to Configure the Language Detector Component
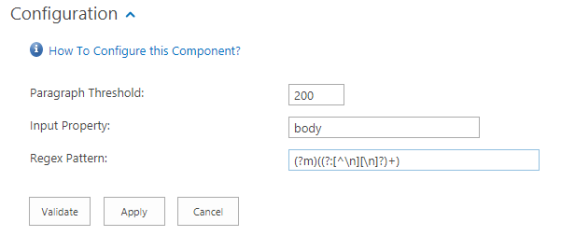
- Open your Language Detector component.
- Paragraph Threshold - Minimum length of paragraph threshold.
- Input Property - Property that you want to process.
- Regex Pattern - Pattern to be used to split the content of documents in paragraphs. (only modify for custom paragraph splitting)
- Click Apply.
|
Output Property |
Description |
|---|---|
| DetectedLanguages | Text-multi |