How to Provide Your Training Data
About Training Data
Before proceeding examine your training data and ensure your data meets the following requirements:
Your training data must be:
- Based on keywords inside the document
- Based on word association
- Based on similar documents
- DO NOT provide documents with a wide range of numerical data, such as:
- Graphs
- Charts
- Tables
- Scientific drawings or schematics with numerical values
For information about how
- For Information, see https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-module-reference/multiclass-decision-forest
How to Map Your Untrained Machine Learning Provider to a Taxonomy
- You can map your untrained Machine Learning Provider to a new or existing taxonomy.
- Click "Manage Taxonomies" from the left-side navigation.
- Select a taxonomy.
- Enter a new taxonomy in the "Enter new taxonomy name" text box and click Create and then select the new taxonomy from the list shown,
or Select an existing taxonomy from the list shown.
- Enter a new taxonomy in the "Enter new taxonomy name" text box and click Create and then select the new taxonomy from the list shown,
- The Rules page opens.
- To add a term (node), right-click your Taxonomy at the top of the right pane and select "Add term" from the sub-menu that appears.
- Enter all the terms you have training data for.
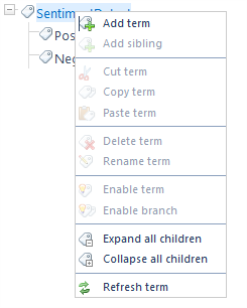
- Enter all the terms you have training data for.
- In the following example, the Taxonomy "SentimentDetect" has two terms defined
- Positive
- Negative
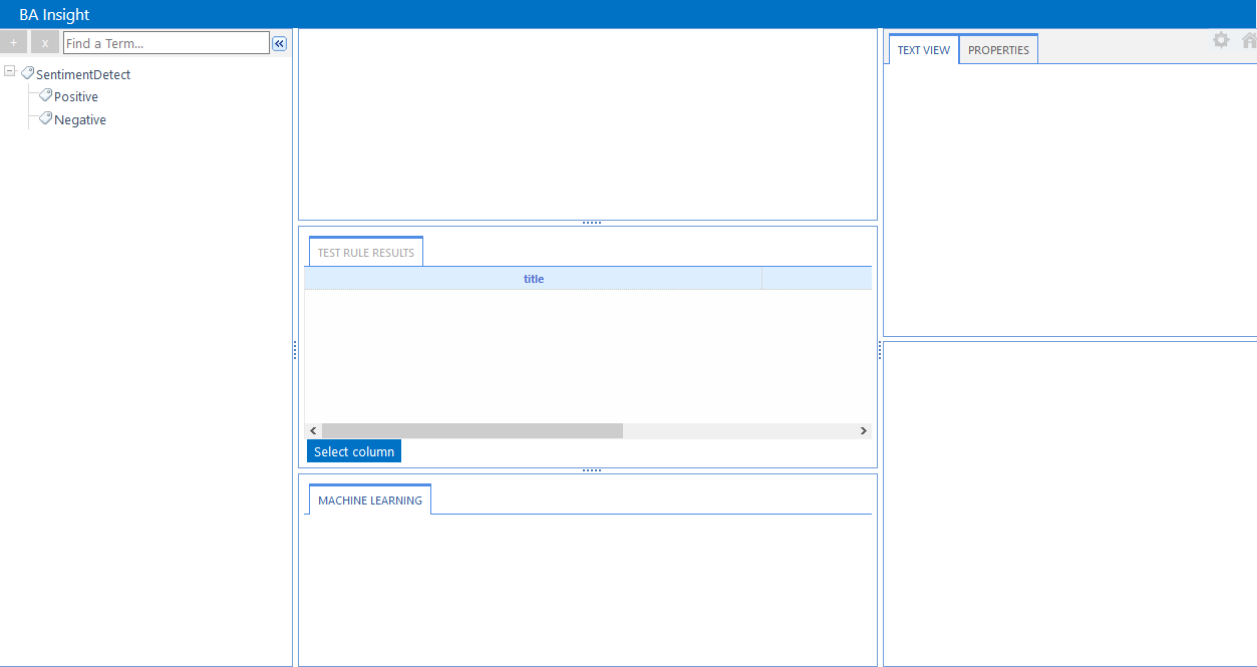
- These terms are detected by the ML algorithm in conversation or text that it processes.
- Select your Taxonomy and then select the (available) ML provider for the taxonomy from the drop-down menu in the MACHINE LEARNING tab.
The setting is automatically saved.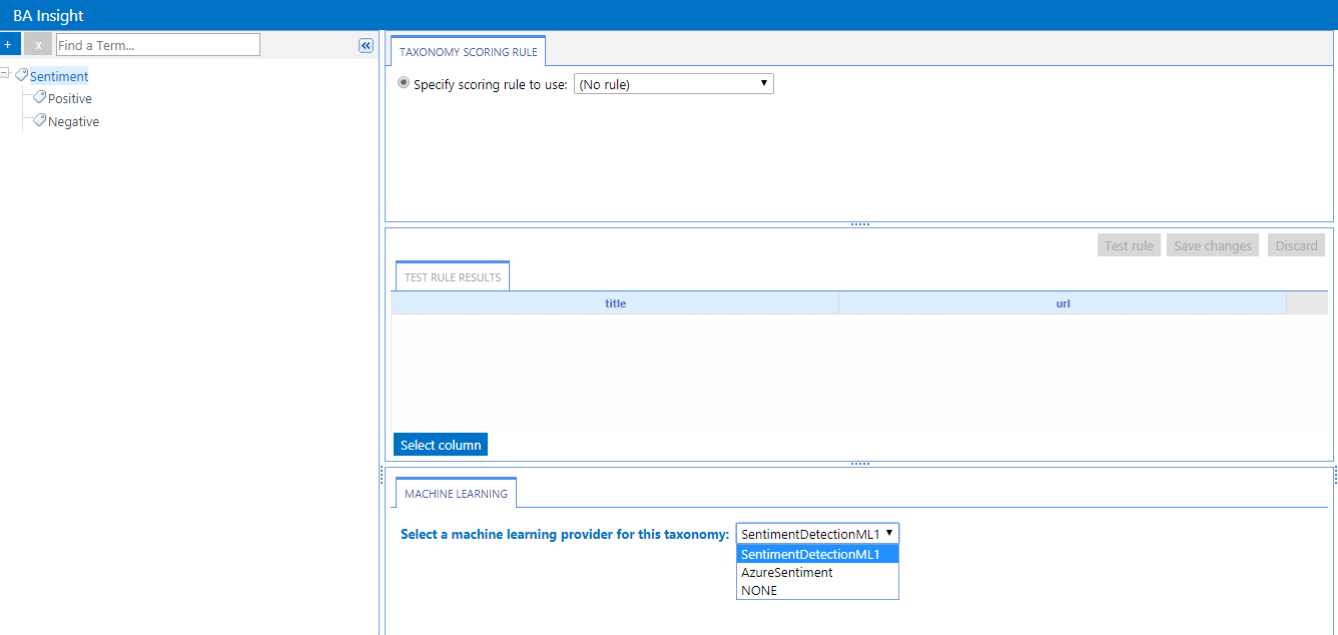
- Now set the training data for your terms or "nodes."
- Note: Training data can not be set for the root ("SentimentDetect," in the example below).
- Note: Training data can not be set for the root ("SentimentDetect," in the example below).
- Select the node you want to add training data for.
- In the example below, we select the Positive node.
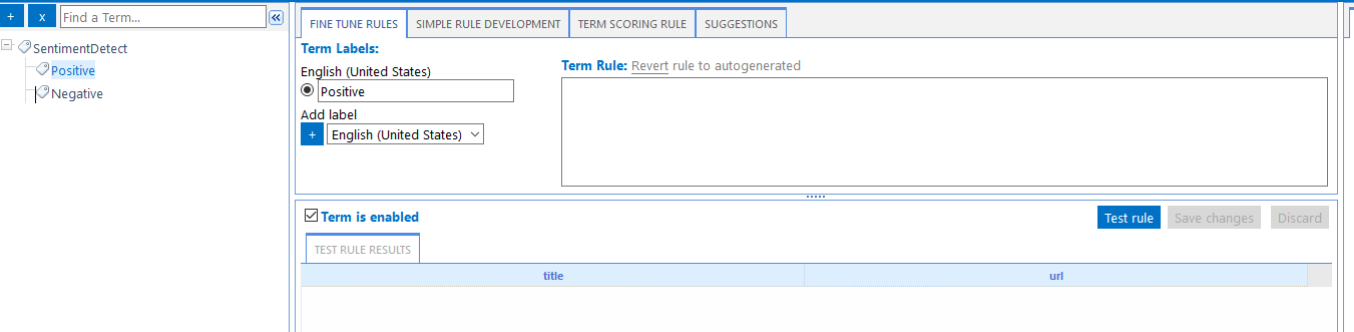
- In the example below, we select the Positive node.
-
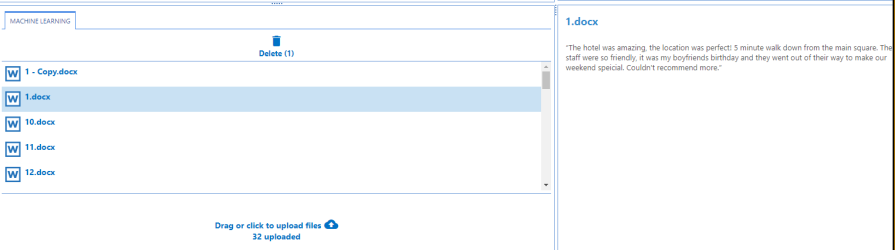
Drag-and-drop or click the icon at the bottom of the MACHINE LEARNING tab to add the documents that contain training data.
-
See the example below (the documents added contain "positive" and "negative" language).
Google ML requires at least 30 training documents per node, but recommends 100. The more documents used, the more accurate the ML.
-
- Selecting the document in the left-side pane reveals the document contents on the right side.
- Add training documents for all nodes.
Set Rules for Your Terms (Nodes)
Term rules support the following rules:
-
RegEx
-
Kusto Query Language (KQL)
For each term or "node" the ML rule used when processing training documents is shown in the Term Rule dialog box.
You can set the Term Rule for each term (or node) as follows:
- No rule
- Default (auto-generated) rule
- Combination of complex (RegEx/KQL) rules and ML rules
If the termor ML rules find a match in a training document, the tag is applied.
- Enter the Term Rule for each term in your taxonomy. Click Save changes after each rule is entered.

To clear the training data for a Machine Learning Provider, use the "Clear All Training Data" button next to the Train button discussed in the following section.
Train Your Machine Learning Provider
Once the procedures above are complete, you are ready to train your Machine Learning Provider.
- If you are still on the Rules page, click back in your web browser.
- Select Machine Learning Providers from the left side navigation.
- The available ML providers appear. Note: The Status of your ML provider will be "Needs Training."
- Select your Machine Learning Provider by clicking its name.
-
Click the Train button at the bottom of the screen.
Note: Machine learning training is not Incremental, it is Full. If you add documents to your ML provider, a full training process must be run to incorporate all data.
- Depending on how much data you provide your ML provider, and how many items, the training process can take 3-6 hours or more.
- Proceed to set up your Rules Engine Pipeline stage next (below), the tagging engine which applies the ML provider taxonomy.
How to Retrain Your ML Provider with New Documents (Data)
- Re-open your ML provider and add more documents, using the steps in the procedure above.
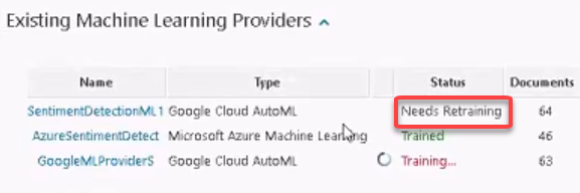
- The Status of the ML provider under "Existing Machine Learning Providers" changes from "Trained" to "Needs Retraining" as it contains new data that has not been processed.
- Repeat steps 2-5 above to retrain your ML provider and incorporate the new data.
Rules Engine Pipeline Stage
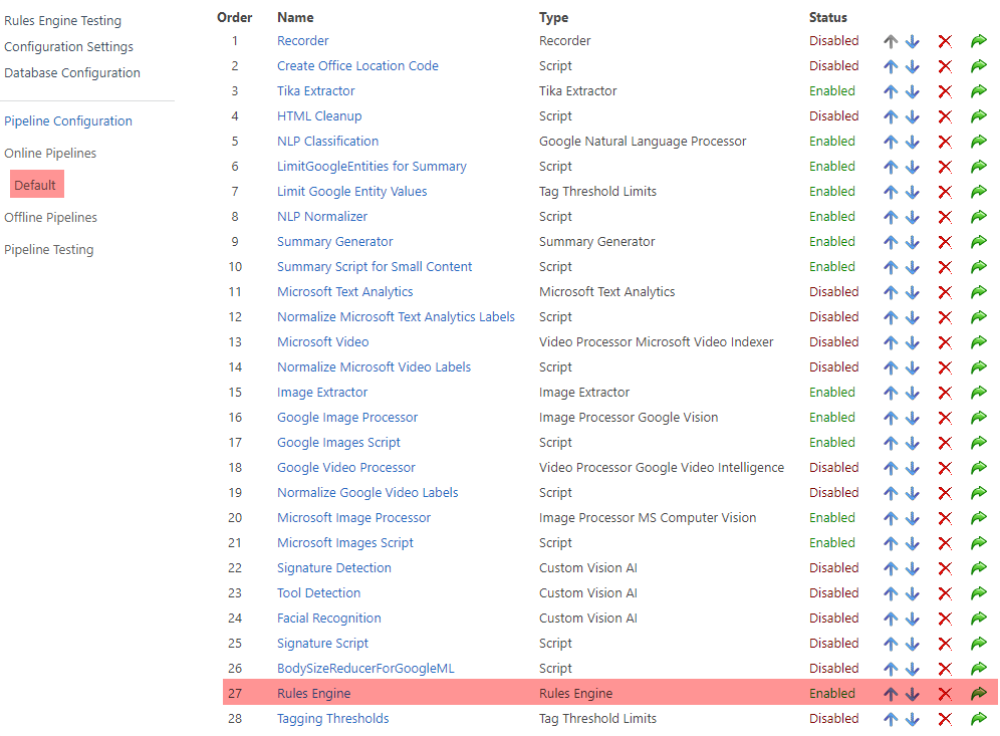
For ML providers to tag, you must add the Rules Engine pipeline stage.
See the following graphic.
How to Test Your ML Provider Taxonomy
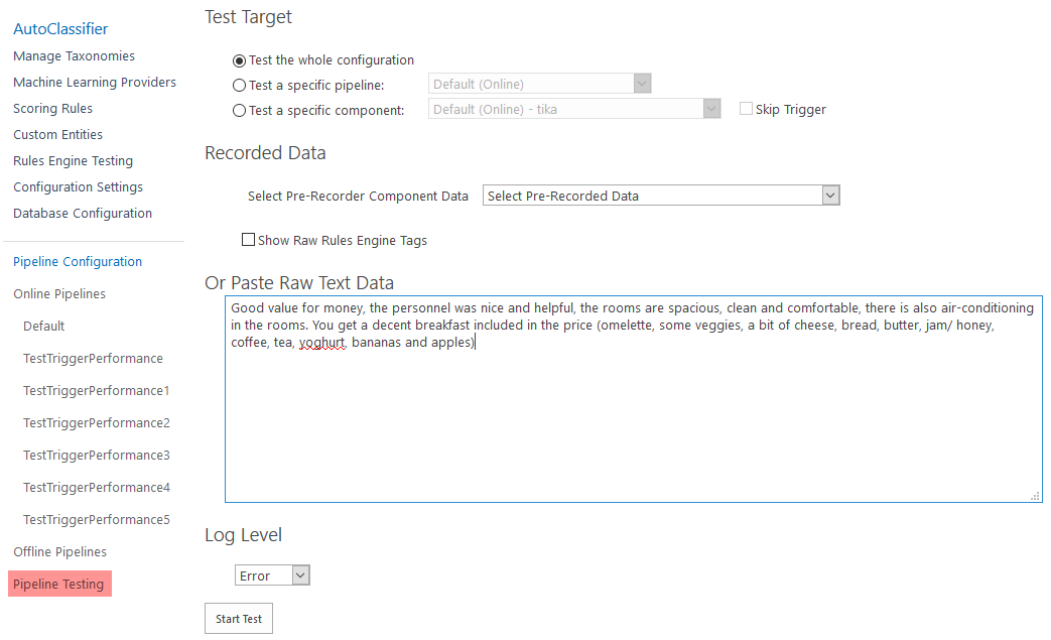
To see a sample of which tags you receive based on ML classification, go to the Pipeline Testing page, highlighted below.
- Select Pre-Recorded data from the drop-down menu, or else enter in raw data taken from one of your training documents.
- For insight into ML tagging, check the Show Raw Rules Engine Tags check box to view which tags are generated from each output property.
- Set your Log Level using the drop-down menu.
- Click the Start Test button at the bottom of the screen.
- The test runs.
Standard Output
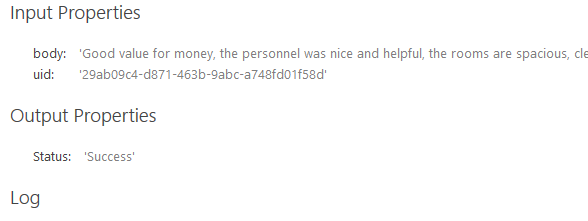
The following is returned if the Show Raw Rules Engine Tags check box is NOT checked:
- Input Properties
- body: Raw Text Data value
- uid: Unique Identification Number
- Output Properties
- Classification Tags: Tags generated by your Taxonomy
- Status: Test status
Expanded Output
The following is returned if the Show Raw Rules Engine Tags check box is checked:
- Input Properties
- body: Raw Text Data value.
- uid: Unique Identification Number
- Output Properties
- RulesEngine: Tags generated from rules.
- [ML Provider]: Tags generated by your Taxonomy.
- Status:
- Test status
- Values are "Success" or "Failure"
- To debug test failures, set your log level to "debug" using the drop-down menu above the message
