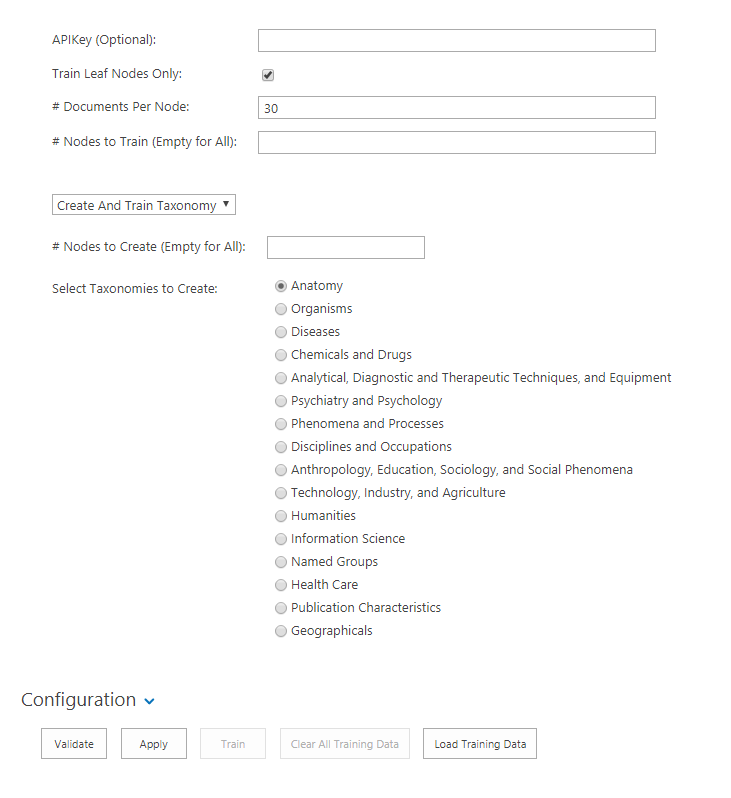
Machine Learning Training Data
Training data can be used with Machine Learning to create and train Machine Learning Classification Algorithms.
-
Training data uses publicly available data from NCBI (National Center for Biotechnology)
-
Available data sets:
- PubMed
- PMC
To use training data:
- Open or create an existing Machine Learning Provider
- Expand the" Available Training Data" section
- Select an available Training Set:
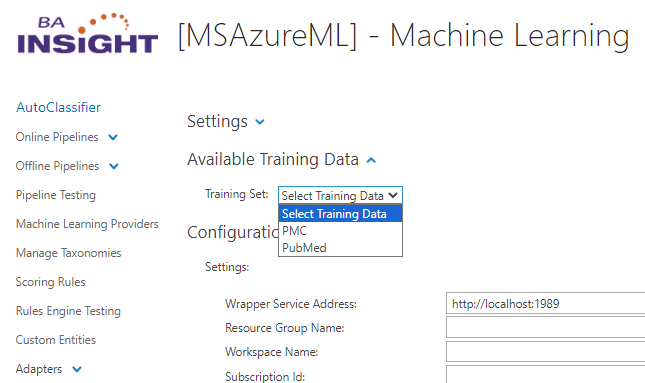
- Configure the "Available Training Data" options:
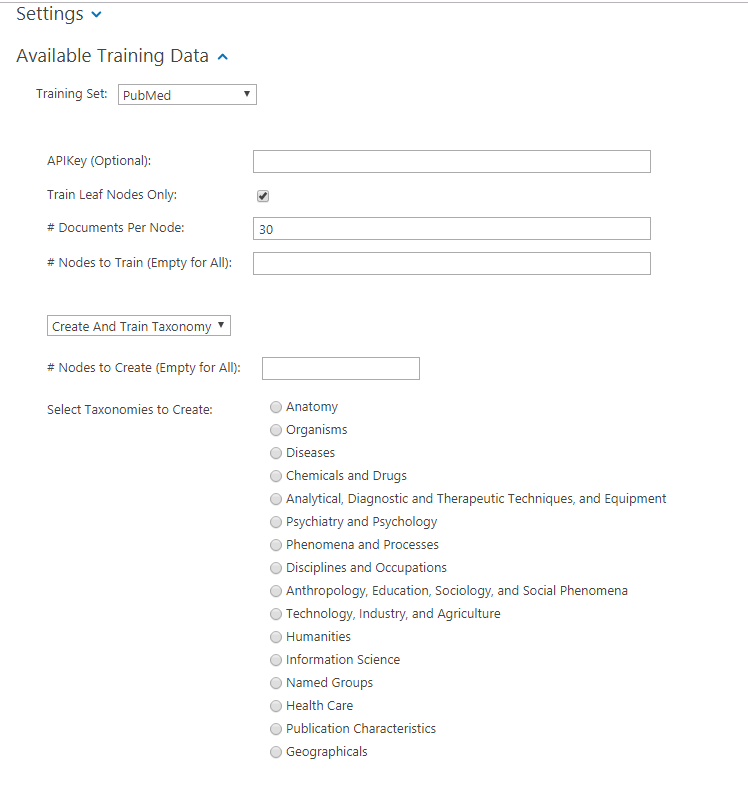
- APIKey (Optional):
- NCBI provides the ability to register for an API Key which enables greater concurrent requests when retrieving data.
- The current code throttles to the allowable limit of 3 concurrent requests per min.
- NCBI provides the ability to register for an API Key which enables greater concurrent requests when retrieving data.
- Train Leaf Nodes Only:
- When retrieving training data, the option is available to train all nodes in the Taxonomy Tree or just the leaf nodes. (The lowest node).
- To train only leaf nodes and not the whole hierarchy select this option.
- # Documents Per Node:
- Specify the number of Documents to use per Node when training.
- The more documents used typically provides more accurate results but requires longer training time.
- Specify the number of Documents to use per Node when training.
- # Nodes to Train:
- When testing, the number of Nodes to attach training data to can be limited by specifying a number.
- Example: If only Train Leaf Nodes is selected and "20 Nodes to Train" is selected, then only the first 20 Leaf Nodes will have training documents attached
- When testing, the number of Nodes to attach training data to can be limited by specifying a number.
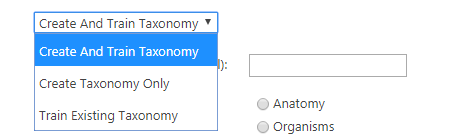
- Select a Creation/Training Option:
- Create and Train Taxonomy: Create both a new taxonomy and train the nodes per the configuration options
- Create Taxonomy Only: Will create a new taxonomy but not train any nodes
- Training Existing Taxonomy: If a Taxonomy already exists the process will train the taxonomy
- Nodes to Create: Option to limit the number of taxonomy nodes to create when testing
- Hit Load Training Data.
- Depending on the options this can be a time-consuming process.
- When completed, a taxonomy will be available with training data, depending on configuration, and attached to the Machine Learning Provider.
- Depending on the options this can be a time-consuming process.
- Hit Load Training Data.