How to Extract Information from Images
About
Use the Microsoft Computer Vision OCR component to extract OCR information from images and PDF files using the Microsoft Computer Vision READ API.
Supported file formats:
- JPEG
- PNG
- BMP
- TIFF
How to Add Microsoft Computer Vision OCR to AutoClassifier
- Navigate to the AutoClassifier Online Pipelines component page.
- Expand New Component at the bottom of the page.
- Select Microsoft Computer Vision OCRfrom the component list
- Name your new Filtering component.
- Click the Add button.
- Click Apply to save your changes.
How to Configure Microsoft Computer Vision OCR Component
Trigger
All component triggers are set using the same method and instructions. See How to Classify Images.
Configure the Trigger so that only those documents to be OCR'd are passed to the API.
Passing unsupported file types or documents you do not desire to OCR results count as API requests.
This results in additional cost and time/performance.
Settings
-
Name your component appropriately.
-
Check the Component is enabled checkbox (enabled by default).
Caching
When caching is enabled the stage does not make a request to the API if both:
- The document has been OCR'd previously
- The cache is not expired
Options
- Clear Cache on Configuration Change
- If enabled, any change to this stage removes all items from the cache
- Expiration
- Never: Cache never expires
- Sliding: Cache expires x days after the item is cached.
- Absolute: Cache expires after a set date.
- Caching is enabled
- Enables caching of documents
Configuration
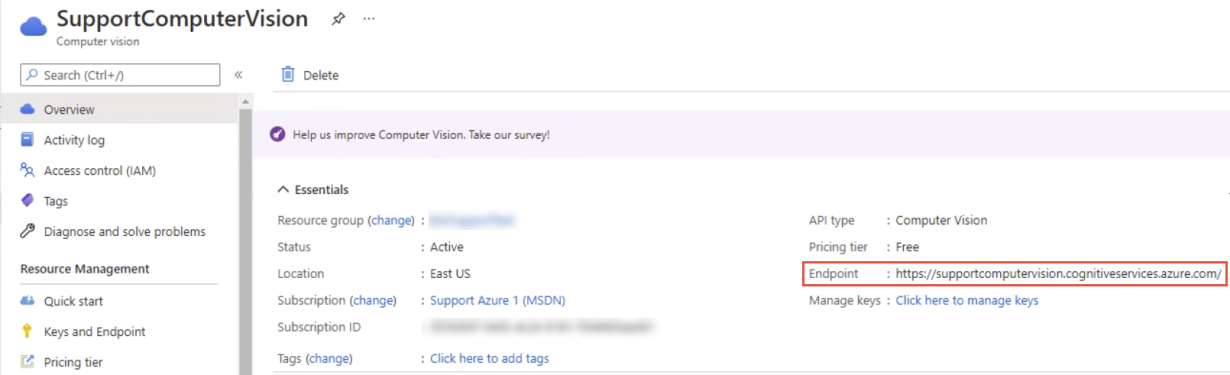
- Endpoint url: Enter the URL used to make calls to the Computer Vision API. The "computer vision" resource in the Azure Portal contains your endpoint URL. See the example below:
- Api Key: Enter API key obtained when configuring Microsoft Computer Vision.
- Total time to wait for processing: Specify the time to wait, in seconds, before retrying if API calls time out or fail.
| Output property | Description |
|---|---|
| MSComputerVisionOCR | Text - Multi |