How to Improve Search Results Accuracy
Use datasets to improve search results accuracy by adding the metadata from one content source to another content source.
-
Datasets are a type of content source that have limited functionality when used alone.
-
However, you can use datasets to enrich indexed content with metadata from another, associated content source.
-
-
Each dataset is a secondary content source.
-
A single content source can have multiple datasets where each dataset has its own set of metadata.
-
You can specify metadata (custom or from the dataset columns) for your datasets using the Dataset Metadata page that is similar to the Content Metadata page.
Improve Datasets to Improve Search Results
For example, you might index employee profile content.
-
To perform this indexing operation, you link the employee profile master record to the second dataset using a common
employeeIDfield. In this example:-
The second source contains the employee status which might be
active,on leave, and so on. -
By joining this employee status record (as a dataset) with the master record dataset, your indexed record is enriched with its properties.
-
-
You can also associate one or more dataset members with a content source column.
-
You might specify
DS_as the prefix for your dataset metadata in order to track this metadata with the content metadata (ESC_) in the index. -
The dataset metadata, like the content metadata, is appended to the item that is indexed.
All the metadata, regardless of whether the metadata came from the content source or from the dataset, is treated equivalently.
Map the Data in Your Content Source to a Database Column to Index Related Metadata
- Content Sources > <your Web Service Connector> >
 > Edit > Dataset Mappings:
> Edit > Dataset Mappings:
See the Dataset Mappings page.
- Add dataset mappings:

-
Parameter: Enter, or leave the default [ID].
- Value:
- template: These settings are the default settings and are shown below
- script: Enter a script using Scripts page.
- Pick column: Click and select a database column. See the following example of possible selections.

- Default value: Enter a value, such as
0, to be used if no value is found.
Note: Unless you specify a prefix that is different from the prefix ESC_ used for content sources, there is no way to track the source of your metadata.
Dataset changes are not propagated during a recrawl operation unless the document in the content source changes.
Setup the Required Cache Database and Select Enumeration and Filter/ACL Scripts
- Content Sources >
<your Web Service Connector>> > Edit > Advanced:
See the Advanced page.
-
Cache database
-
Required
-
Leave the default selection (the cache database that you specified during the install operation), or use the drop-down list box to select a different cache database.
-
- Enumeration process
- Leave the Use default selection.
- Alternatively, click Override and specify a script that overrides the default content enumeration.
- Using the examples provided for non-folder-based or the folder-based connectors.

- Filter script:
- Write a custom script to filter database items. For example, if the item cannot be returned,
falseis returned and the value is excluded.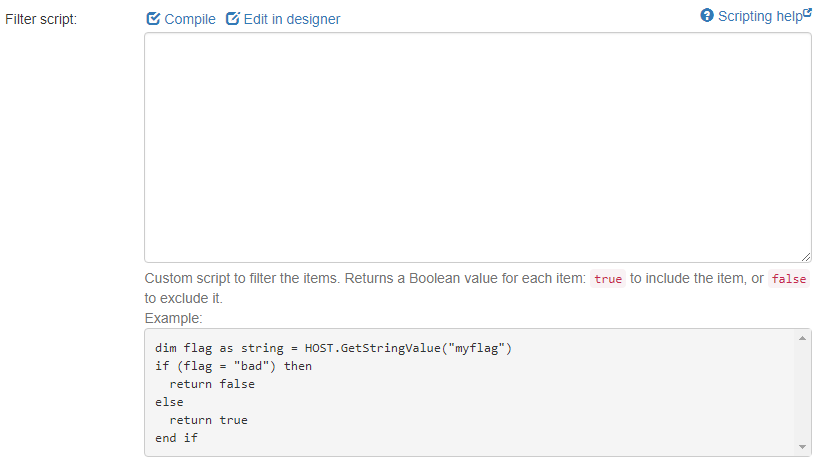
- Write a custom script to filter database items. For example, if the item cannot be returned,
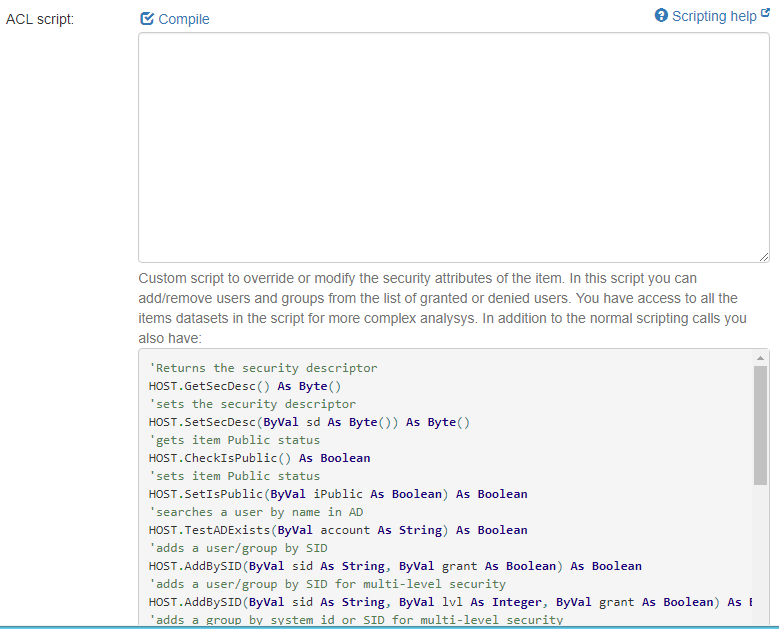
- ACL script:
- Write a custom script to override or to modify the item's security.
- You can choose to add, or to remove, users or groups from the list of users who are either granted or denied access.
- For more complex analysis, access any of the item datasets in the scripting example that is shown in the UI.
- Script library: Use this library to store the Content-wide scripts that you write.
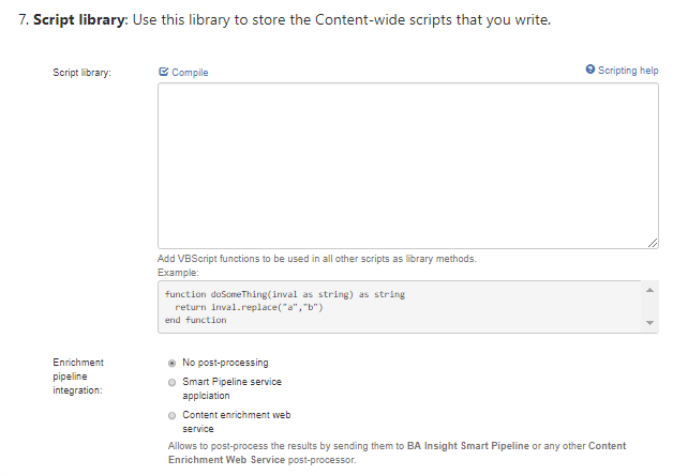
- Enrichment pipeline integration: Optionally, post-process your data using one of the following options:
- No post-processing: By default, no processing is run on your items after they are extracted from the database and before these items are sent to the index.
- Smart Pipeline service application
Content enrichment web service:
For examples using content enrichment, see:- How to Extract Plain Text from Documents
- How to Extract HTML Text and Metadata from Documents
- Compile any of your scripts and click Save if you make any changes.