API stencil
The API stencil will allow a desktop agent to download documents from a specified workflow step. Contact support for more information.
Available connections
There are two outgoing connections from an API stencil: green if the export was successful and red if the export failed.
Configuration
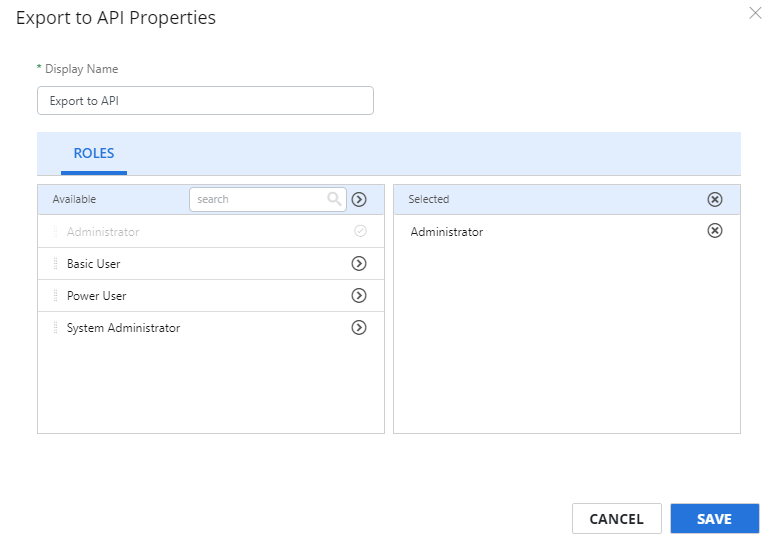
- To access stencil properties, double-click an API stencil. Or, right-click an API stencil and select Properties.
-
Select the role(s) that can perform the export, then click Save.
API Documentation
Overview
In order to use the API, the external agent must first acquire an authorization token by logging in to the Intelligent Capture API. Once the token has been acquired, the agent will query the Export to API step by name and retrieve the pending items. For an individual document, the agent will then request the item stream (PDF document bytes), and once complete, it will update the state of that document to move it along in the workflow.
Acquiring a token
HttpMethod: POST
EndPoint: user/authenticate
Body: LoginRequest
LoginRequest {
username: string;
password: string;
}This will return a LoginResponse.
LoginResponse {
succeeded: boolean;
token: string;
errorText: string;
}The agent should check to determine if the login request was successful.
Subsequent API endpoints require the token to be included as part of the call in the HTTP Header Authorization
Authorization: BEARER TOKEN
Note: The user must be assigned to a role that is selected in the Export to API stencil configuration to allow access to the rest of the endpoints for the workflow step.
Enumerating the list of pending items
HttpMethod: GET
EndPoint: /exportqueue/WORKFLOWNAME/WORKFLOWSTEPNAME/PAGENUMBER/PAGESIZE
WORKFLOWNAME: The name of the workflow. This must be an exact match including case and spacing.
WORKFLOWSTEPNAME: The name of the workflow Export to API step. This must be an exact match including case and spacing.
PAGENUMBER: The page number of the set of data requested.
PAGESIZE: The number of items per page to return.
This will return an ExportWorkItemsResult.
ExportWorkItemsResult {
success: boolean;
errors: string[];
object: ExportWorkItemsResultObject;
}ExportWorkItemsResultObject {
itemsTotalCount: number;
exportWorkItems: ExportWorkItem[];
}ExportWorkItem {
id: string;
owner: string;
metaData: object; // see MetaData
filename: string;
fileType: string;
size: number;
pageCount: number;
}MetaData is an object which contains the data fields associated with the document.
Each MetaData property points to an object that contains the details about that data field.
{
name: string;
value: string;
valueType: MetaDataValueType;
validity: MetaDataValidity;
}
enum MetaDataValidity {
unknown = 0,
valid = 1,
suspicious = 2,
notValid = 3,
}
enum MetaDataValueType {
String = 0,
LineItems = 1,
}Getting the document stream (PDF Bytes)
HttpMethod: GET
EndPoint /exportqueue/stream/ID
ID: The ExportWorkItem id for the document.
This will return the byte stream of the associated PDF document.
Updating the document status
HttpMethod: POST
EndPoint: /exportqueue/completed/ID/STATUS
ID: The id of the ExportWorkItem for the document to update.
STATUS: true or false - indicating whether or not the item was successfully processed (true). This status will cause the appropriate workflow step outcome (success/failed) to be called next for the document.
Body: empty
This will return ProcessWorkItemResult.
ProcessWorkItemResult {
success: boolean;
errors: string[];
}