The process that replies to document requests from Capture OnTheGo App users
The previous process informed the Capture OnTheGo Server that a new document was now available. So Capture OnTheGo App users that have access to this document can now see it and download it from a PlanetPress HTTP Server or a regular Web server. Based on the document’s Capture OnTheGo settings (for more information on this, refer to The process that publishes a Document), the document is either automatically downloaded, or it can be manually downloaded. The actual download of this document is done via a PlanetPress Workflow process that includes an HTTP Server Input task.
The example below is divided into three parts: receiving the request, fetching the document and sending the document.
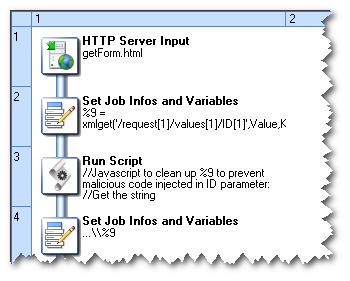
Receiving the request
To begin with, the HTTP Server Input task waits for requests. When a request is received and authenticated, the next task down stores the request’s parameters in a variable. The variable’s content is then processed to remove any malicious code. The following task completes the document’s path by adding the location of the server where the document is actually stored.
Note: To make sure that documents are served only to users of the Capture OnTheGo App, the Input task authenticates download requests, using the authentication key of the Capture OnTheGo Repository. This key can be found in the Parameters section of the COTG Web Administration Panel.
Enter the key in the HTTP Server Input 2 User Options in the Workflow preferences (see HTTP Server Input 2 User Options (PreS) or HTTP Server Input 2 User Options (PlanetPress)).
For further information on how to use and configure the HTTP Server Input task to serve documents over the internet, refer to the Workflow documentation.
If you are having problems downloading forms via HTTPS, this could be caused by a certificate not being valid or installed incorrectly. There are various online certificate checkers, e.g: https://www.sslshopper.com/ssl-checker.html.
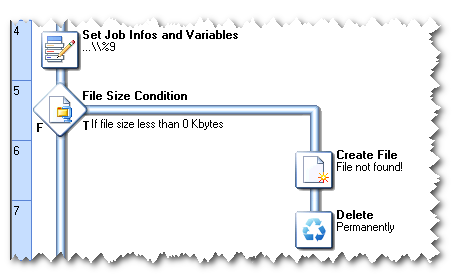
Finding the document
The next part of the process checks whether the requested document can be found or not. If the requested document is less than zero kilobytes in size, it is assumed to be non-existent. When this is the case, a File Not Found document is created, sent to the requesting client, and then deleted from the server.
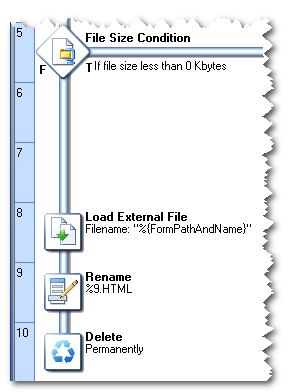
Sending the document
If the requested document is more than zero kilobytes in size, then we know it does exist. In the third part of our process, the document is actually sent to the requesting client. The document is first loaded, renamed to the original name included in the request (the full path is reduced to the file name), and sent to the client. Finally, the document is deleted from the server.
Downloaded PDF documents can then be opened for viewing, and HTML documents can be used to collect information that can then be sent back for processing.