Working with Metadata
A set of special Workflow plugins allows to edit the Metadata during a Workflow process (see Metadata and Metadata tasks). This topic describes what you have to know about Metadata in order to be able to use these plugins effectively.
How data and Metadata influence each other
When Metadata are created, they are based upon a data file. However, modifying one file doesn't automatically change the other, and Metadata aren't reset by default in a Branch, Condition or Loop.
- Modifying Metadata does not immediately modify the data. This is one of the benefits of Metadata because you can sort it, filter it, sequence it, add data to it, without ever modifying the data file itself. This is important because if you, for instance, filter out certain data pages from the Metadata and then save your data file with the Send to Folder task, the full data file is saved, not the filtered one. However in some cases Metadata does affect your output directly (see How Metadata affects the output).
- Modifying data does not immediately modify the Metadata. So, if you have a PDF file with Metadata and you use a PDF splitter, the Metadata information would still reflect the original data, not the split. This can generally be resolved by using the Create Metadata plugin (again).
- Branches, Conditions and Loops (such as the PDF Splitter) do not reset the Metadata. This is important to know in cases where Metadata does affect your output (see How Metadata affects the output). Not handling the Metadata properly in such cases can cause confusing issues because the Metadata and the Data may become out of sync.
How tasks influence Metadata
As a general rule, only Input tasks and Metadata related tasks modify Metadata. There are, however, a few notable exceptions:
- Run Script tasks can modify Metadata using the Metadata API (see Using Scripts).
- Create PDF has the option to reset your Metadata according to the new PDF file.
- OL Connect tasks can add information, such as record IDs, a record set ID or a print job ID, to the Metadata. They put it under 'User defined information' on the Job, Group or Document level.
- The Barcode Scan task can add information to the existing Metadata, and creates it if there is none.
- The Capture-Fields generator, Capture-Fields processor, Capture-Get document and Capture-Find document tasks generate their own Metadata.
- The Lookup in Microsoft® Excel® Documents enhances Metadata fields with information from an Excel spreadsheet, but does not otherwise change its structure.
How Metadata affects the output
By default the data file is not affected when the Metadata are modified. There are however a few situations in which Metadata will or may affect the output.
In OL Connect, output is normally created from records in the Connect database, but options in some OL Connect tasks make it possible to influence the output via the Metadata.
- The Execute Data Mapping task and Retrieve Items task can output records in the Metadata.
- The Create Print Content and Create Email Content tasks have the option to update the records in the Connect database from the Metadata and use the updated records as input.
Note: Date/time values are stored in the OL Connect database as Unix timestamps, i.e. the total number of seconds from the starting time of UTC (Universal Time, Coordinated) to the current time (with zero time zone offset). For instance: 1675950179.
In the Metadata, however, date/time values are represented in the following format: YYYY-MM-DDTHH:MM:SSZ.
In PlanetPress Suite, the Metadata defines the order in which the data is consumed by a Design template. Changing the order and location of the various items means that the final output will be different than the original and will follow the order dictated by the Metadata instead of the order of the physical data.
- When you print a PDF with a Windows Print Queue, the Metadata is inspected to determine whether pages should print or not (see Print using a Windows driver).
- The Create PDF task also takes the Metadata into account.
Output issues caused by Metadata, and how to avoid them
A Branch, Loop (the PDF Splitter, for instance, or the Loop task) and Condition don't reset the Metadata. This can cause confusing issues if they are used in combination with a task that takes the Metadata into account.
To avoid such issues, either regenerate your Metadata inside the (condition) branch or loop as early as possible (see Create Metadata), or use the Metadata File Management to delete the active Metadata file and let the data file be taken into account instead of the Metadata.
Example
Here is an example of an issue that occurs when Metadata is not re-created in a Loop.
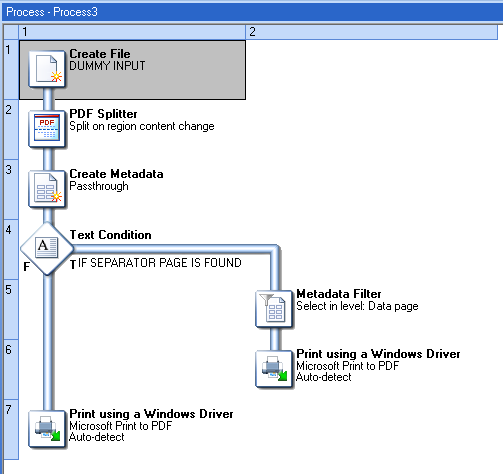
In the following process, the Job file is a PDF that contains several invoices. Some (but not all) of those invoices start with a separator page that you don't want to print. Invoices that don't have a separator page should be printed as-is.
The process would look something like this (by default):
-
Step 2 splits the PDF whenever it encounters a new Invoice Number on the Top Right corner of a page. From this point on, the rest of the process applies to each split (i.e. each invoice).
-
Step 3 checks if the first page is a separator (presumably by looking for some kind of keyword on the page).
-
If a separator page was found, step 4 creates Metadata for the split PDF…
-
...and step 5 filters out the first page (which means the Metadata unselects the first Data Page, in effect "hiding" it from the Print Output task).
-
Step 6 prints the PDF to a printer. When printing a PDF file in passthrough mode, the Metadata is inspected to determine which pages should print or not. In this case, Page 1 is unselected in the Metadata, therefore the printer receives the job starting from Page 2, which is exactly what you want.
-
Step 7 prints the entire PDF since no separator page was found.
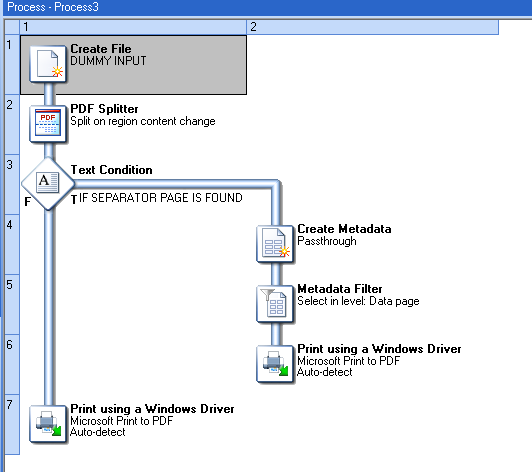
Now here comes the issue:
-
The process moves back up to Task 2 in order to process the second split of the original PDF. The Metadata file still exists in the process! So far, it doesn't impact the rest of the process… but wait…
-
Let's say in step 3 no separator page is found on page 1 of the second split PDF.
-
Step 7 prints that second split PDF… but page 1 is unselected in the Metadata (because the Metadata was carried over from the last split!) so at the very least, you will be missing one page. If the second split has more pages than the first one, other pages at the end will get missing as well, as the Metadata doesn't know about it. Or if it has less pages than the first one, the last pages will be blank.
To avoid running into the issue, you should use the Create Metadata task to re-create the Metadata immediately after every split, thus ensuring that the process cannot, in either branch of the condition, be using the Metadata from the previous split.