How to Classify Images
If you want to classify images within documents, use the Image Extractor component in combination with the components below.
Set up the output from Image Extractor (ExtractedImagesBinaryData) as "Additional Input Property" field for the image processing components.
The accepted extensions field for image processing components is only applicable to image files, not to images extracted from documents or for the documents the image was extracted from.
Image Processor: Custom Vision
This component uses Microsoft Custom Vision AI to analyze images and extract any detected entities.
Prerequisites
Before adding the Custom Vision AI component, ensure that you have completed the following prerequsites:
- Install Visual C++ Redistributable for Visual Studio 2012
- Enable the Windows Server Feature .NET Framework 3.5 Features
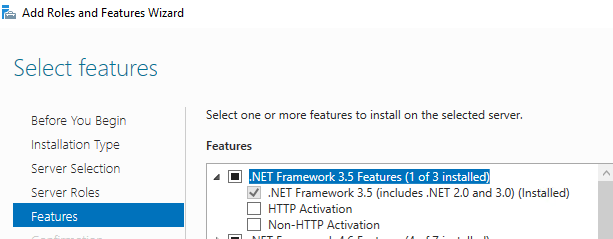
- Navigate to Microsoft Custom Vision AI
- Create a new project
- Click the Training Images tab, upload your training images, and train your model
How to Configure the Custom Vision Image Processor
To configure, use the following image and steps:
-
Open your pipeline.
-
Expand the New Component section.
-
Select Custom Vision AI.
-
Enter a component name.
-
Click the + Add link.
-
Click Apply.
-
Click the name of the component in the ordered list to open it for configuration and specify the following:
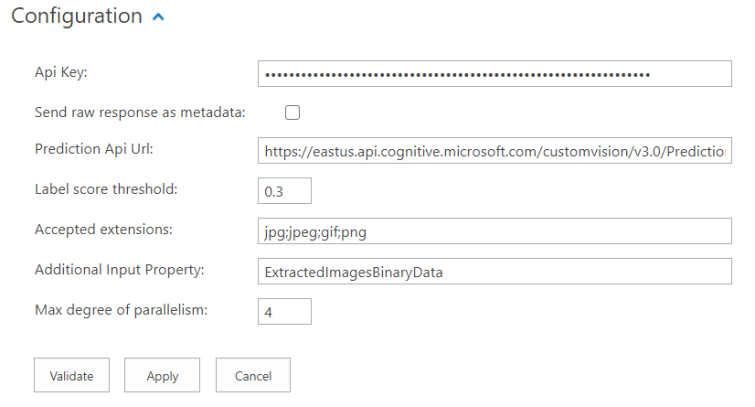
- Api Key:
- Navigate to the newly trained project.
- Click on the cog button and go to project Settings.

- Click Resources > Key
- Copy the Key and paste it in the Api Key field
- Send raw response as metadata: Click to attach the JSON response from Microsoft Custom Vision to the list of output properties.
- Prediction API Url:
- On your trained project click on the Performance tab:
- Click on Prediction URL.
- Copy the URL under "If you have an image file:".
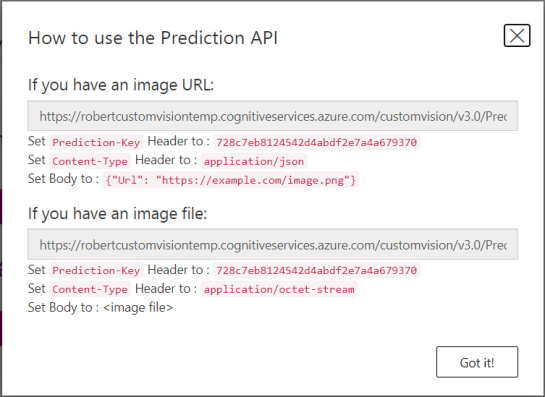
- Paste the URL in the Prediction Api Url field.
- On your trained project click on the Performance tab:
- Label score threshold:
- Specify a value between 0 and 1 to represent the minimum confidence score accepted for an entity label.
- Specify a value between 0 and 1 to represent the minimum confidence score accepted for an entity label.
- Accepted extension:
- Specify the image file extensions you want to process.
- Separate these extensions using a semicolon (
;).
- Additional Input Property:
- Specify an input property of type
List<byte []>that represents additional images that are processed by the pipeline. - For example, a list of all images extracted previously from a document.
- Specify an input property of type
- Max degree of parallelism:
- Enter a number to specify the maximum degree of parallelism
- Enter a number to specify the maximum degree of parallelism
- Api Key:
Input Properties
File RawData- (Optional) The property specified in the Additional input property configuration option.
Output Properties
|
Property |
Type |
|---|---|
|
|
Text – Multi |
|
|
Text – Multi |
RawResponse
|
Text – Multi |
High Data Usage: Save Money by Using a Trigger
To help you avoid accidentally high cloud data costs, BA Insight designed a predefined "trigger" for the NLP component:
- This is applicable only for AutoClassifier version 5.0 and later.
- The trigger is enabled by default, in sample form.
- The trigger provides sample code that includes the sources to process, (with sample values).
- You must modify the trigger code according to your needs.
Caution: If you do not implement this trigger, you may incur high data costs from your cloud data provider. For example, when crawling 5 different content sources with a total of 1M items, a high number of documents processed for Natural Language extraction can generate high cloud data costs.
Use the following steps:
- Add the desired component, normally.
- When configuring the component, expand the Trigger section and adapt the predefined trigger to your needs.
- Continue with component configuration.
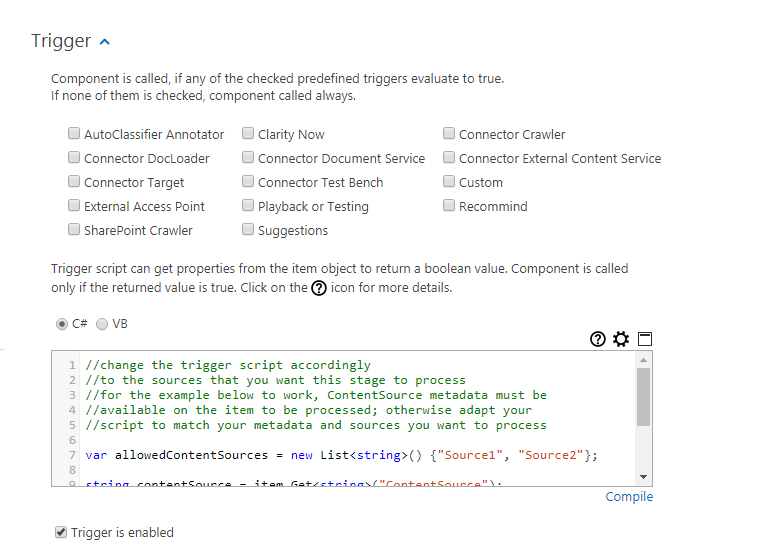
The predefined (modify before using) script value:
//change the trigger script accordingly
//to the sources that you want this stage to process
//for the example below to work, ContentSource metadata must be
//available on the item to be processed; otherwise adapt your
//script to match your metadata and sources you want to process
var allowedContentSources = new List<string>() { "Source1", "Source2" };
string contentSource = item.Get<string>("ContentSource");
if (string.IsNullOrEmpty(contentSource) ||
!allowedContentSources.Contains(contentSource))
return false;
return true;The Components affected by this change are all the BA Insight components that make API requests to Microsoft:
- Microsoft Text Analytics
- Custom Vision AI
- Image Processor MS Computer Vision
- Video Processor Microsoft Video Indexer
How to Trigger Your Pipelines Only for Video Files
The script below can be entered into the code window on the Trigger page. This script runs only if the file extension detected is a supported video format.
- Add to the script only the formats you truly wish to process.
- Adding all the supported video file extensions is unnecessary and inefficient.
This aids you in reducing data usage, thereby saving money.
For more on using Pipeline Triggers, see Add Triggers to Determine When Your Pipelines Run.
// add here all allowed extensions, but always in lowercase
var allowedExtensions = new List<string>(){"mpeg4", "mp4", "avi"};
string fileext = item.Get<string>("escbase_fileextension");
if(fileext!=null)
{
if(allowedExtensions.Contains(fileext.ToLower()))
return true;
}
return false;Image Processor: MS Computer Vision
This component uses the Microsoft Computer Vision API to analyze images and extract detected text and concepts.
How to Configure the Microsoft Computer Vision Processor
To configure the Microsoft Computer Vision Processor use the following image and steps:
-
Open your pipeline.
-
Expand the New Component section.
-
Select Image Processor MS Computer Vision.
-
Enter a component name.
-
Click the + Add link.
-
Click Apply.
-
Click the name of the component in the ordered list to open it for configuration.
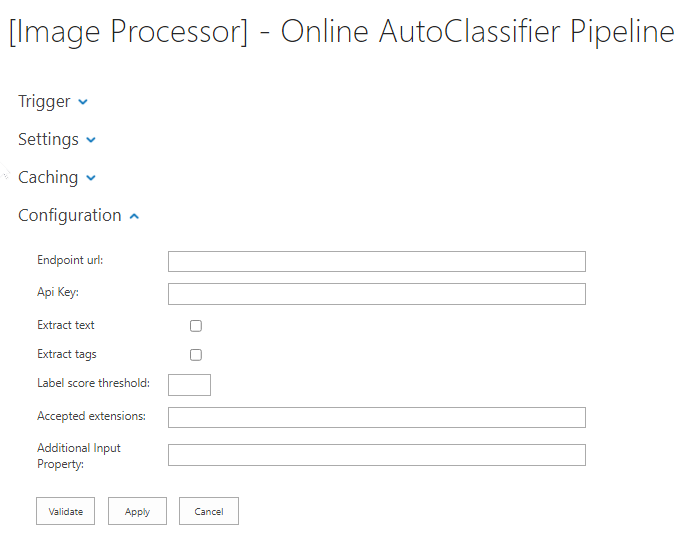
- Endpoint Url: This is the endpoint URL that was used when configuring the Cognitive Services instance.
- Api Key: This is the API Key obtained after configuring the Cognitive Services API.
- Extract text: If this is selected, OCR is enabled (any text present in the images will be extracted in a separate property).
- Extract tags: Select this to enable label/object recognition.
- Label score threshold: Specify a value between 0 and 1 to represent the minimum confidence score accepted for an image label.
- Accepted Extensions: These are the image file extensions that you want to process with the Cognitive Services API (the API only supports the following image formats: JPEG, PNG, GIF, BMP)
- Additional input property: Specify an input property of type
List<byte []>representing additional images to be processed by the pipeline. For example, a list of all the images previously extracted from a document. - Cached data validity in days: Specify the amount of time in days that the image tagging data is cached. If the same image is received by the stage multiple times, the API is only called once and it reuses the cached result in the subsequent requests if the cache is valid
Input Properties
File RawData- (Optional) The property specified in the Additional input property configuration option.
Output Properties
|
Property |
Type |
|---|---|
|
|
Text – Multi |
|
|
Text |
MSAllLabelsWithScore
|
Text – Multi – each entry is in the following format: Label;Score |
Image Processor: Amazon Rekognition
This component analyzes images and extracts detected text and concepts detected.
- This component uses Amazon Rekognition API
How to Configure Amazon Rekognition Image Processor
To configure the Amazon Rekognition use the following image and steps:
-
Open your pipeline.
-
Expand the New Component section.
-
Select Image Processor Amazon Rekognition.
-
Enter a component name.
-
Click the + Add link.
-
Click Apply.
-
Click the name of the component in the ordered list to open it for configuration.
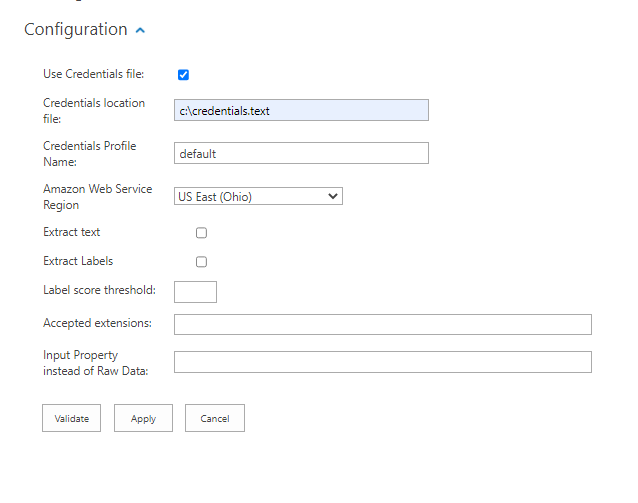
- Check Use Credentials file to use a credentials file
-
AWS Credentials file location: Enter the location of AWS Credential file. For example: C:\Users\Luca\Desktop\credentials.txt
Example AWS Credentials File
[{profilename}]aws_access_key_id = {accessKey}aws_secret_access_key = {secretKey} - Credentials Profile Name: Enter an AWS Profile Name for the Credentials File
or Use API & Secret Access Key directly.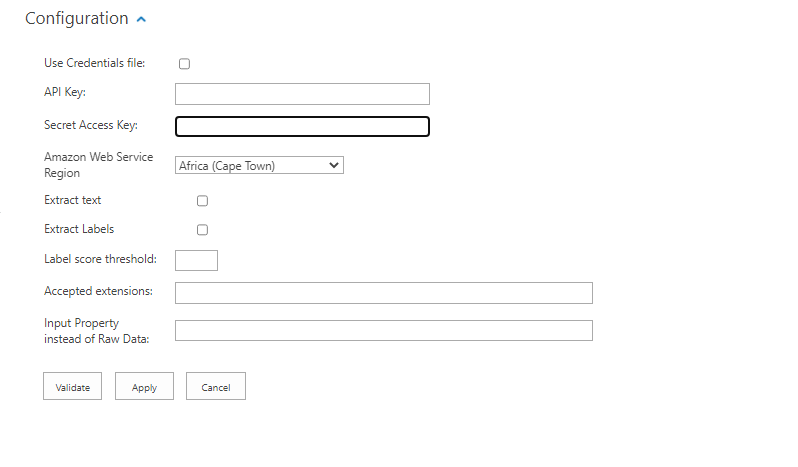
- Api Key: Setup your Amazon Rekognition, obtain an API key, and enter your key into this field.
- Api Secret: Enter the API Secret key.
- Access Key: This is the Amazon account access key to be used
- Secret Access Key: This is the Amazon account secret access key to be used
- Amazon Web Service Region: Select the Region of your Amazon Web Service. The supported Regions for Amazon Rekognition are documented here.
- Extract text: If selected, OCR is enabled (any text present in the images will be extracted in a separate property)
- Extract tags: This enables label/object recognition.
- Label score threshold: Specify a value between 0 and 100 that will represent the minimum confidence score accepted for an image label.
- Accepted Extensions: These are the image file extensions that we want to process with the component (the API only supports the following image formats: JPEG, PNG)
- Additional input property: Specify an input property of type
List<byte []>representing additional images to be processed by the pipeline. For example, a list of all the images previously extracted from a document. - Cached data validity in days: Specify the amount of time in days that the image tagging data is cached. If the same image is received by the stage multiple times, the API is only called once and it reuses the cached result in the subsequent requests if the cache is valid
Input Properties
File RawData- (Optional) The property specified in the Additional input property configuration option.
Output Properties
|
Property |
Type |
|---|---|
|
AWSExtractedLabels |
Text – Multi |
|
AWSExtractedText |
Text |
| AWSAllLabelsWithScore | Text – Multi – each entry is in the following format: Label;Score |