How to Extract Document Sections Using Headers
About
The Section Headers Extractor component is an AutoClassifier pipeline that extracts section and sub-sections from structured documents.
-
This information can then be used in the Section Information Extractor pipeline stage.
-
For example, documents such as contracts, or any document that respect a specific structure can be targeted for use with this component.
These documents can include sections such as:
- Articles
- Declarations
- Clauses
- Line item requirements
Structured Document Example: Contract


- Specific parts of the document can be captured as metadata
- This enables you to capture the document as specific sections and sub-sections.
- Information extraction can be performed as a later, secondary step, using natural language processing (NLP).
- Note that any NLP pipeline stage is ordered BEFORE the Section Headers Extractor pipeline stage.
- Section Headers Extractor is not a stage that should be enabled during production crawls or actual indexing time.
- This is a helper component that should be used during Section Information Extraction configuration phase.
- It helps discovering what possible section headers are available across your data.
- For example, you enable this stage while running several pipeline testing actions, and it will capture the section headers for the documents that were processed.
- Then, you will have an overview and a csv file that contains the detected section headers.
- Also, to extract section headers from a large set of documents, you can enable this component when running a Connectivity Hub Null Target Sync.
- This way, all the documents from the content source will run through this stage and all section headers will be extracted.
- Finally, you will end up with a CSV containing all section headers extracted that can be post processed and then imported in Section Information Extraction stage.
- After you completed section extraction and you are satisfied with the headers set extracted, this component should be disabled and only re-enabled when needed.
Pipeline Order
Before continuing note that the order of your pipelines is important.
The Section Headers Extractor pipeline stage requires the following order:
- Tika: The Tika pipeline must be before all stages that need
document bodyto be extracted and used for processing, including the Section Headers Extractor stage.- Note: "Ignore white space" setting in Tika Component configuration must be disabled.
- Section Headers Extractor: This pipeline stage.
Sample Order
For example, a viable pipeline order would be:
- Tika
- Section Headers Extractor.
How to Configure the Section Headers Extractor
Use the following instructions to configure the document Section Headers Extractor component.
- Add the Component.
- Existing Components: Click the named link for this component to see the Configuration section:
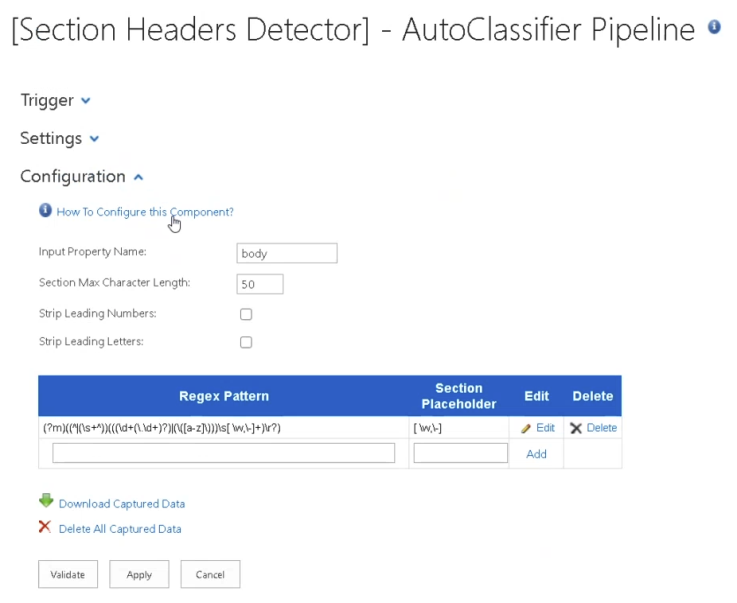
- Input Property Name:
- Specify the input properties, such as body, Heading, etc., that are used to send the web service request.
- Uses body by default. Property names must be separated by commas (
,). - If an external web service expects a property with a different name, the following syntax can be used:
originalName->modifiedName
- Section Max Characters Length: Threshold set to limit amount of characters of a document section. For example, if set to 2500, a document clause that is captured that includes more than 2500 characters, is cropped down to 2500 characters,
- Strip Leading Numbers: Removes any preceeding numbers from a Header. For example, "2.1" Check to enable.
- Strip Leading Letters: Removes any preceeding letters from a Header. For example, "A." . Check to enable.
- Regex Patterns:This table defines the set of regex patterns used to capture section headers. The stage comes with a predefined regex expression that captures the most commonly used section headers in documents.
- Regex pattern: the actual regex pattern that will match the section header
- Section Placeholder: A sub-string (sub-set) of the regex pattern defined above that will be replaced with the actual matched value, with the scope of generating a section specific header in the CSV, to be used in Section Information Extractor as in the example below:
- Note how the Section Placeholder ( [\w,\-] , which in regex language means any word occurrences) was replaced with the actual match values:
- Common Area and Common Area Defined in the final Header Pattern to be used for Section Extraction

- Common Area and Common Area Defined in the final Header Pattern to be used for Section Extraction
- Note how the Section Placeholder ( [\w,\-] , which in regex language means any word occurrences) was replaced with the actual match values:
- Edit: Click to edit the patterns
- Delete: Delete the pattern entry.Regex Example
In the example below, the sample contract at the top of this page and the Regex pattern shown here is used to create the .csv file in "Sample Captured Data," (below).
- Download Captured Data: Click this link to see the data from your document set that this pipeline has captured.
- This can be very useful for training purposes as the pipeline reveals the various sections that exist within your documents.
- The following data is captured from your documents:
- Value: The extracted Header text.
- Header Patterns: The header pattern with extracted header values as defined by your regex pattern.
- Footer Patterns (optional): When a document is scanned by AutoClassifier, one header pattern is discovered, and once a second, different header pattern is encountered, the application understands the first header pattern is complete and has ended.
- Hits: The number of times this header value was discovered in documents. If a specific header value was found in 10 different documents, the hit number would be 10.
Sample Captured Data (.csv file)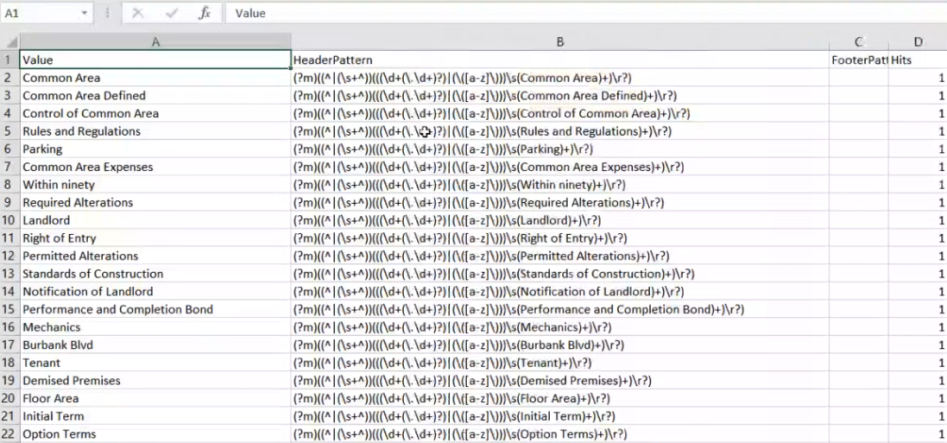
- When finished click Apply.
- Your pipeline stage is configured.
- Configure more sections as you desire.
Import Results into Section Information Extractor Stage
-
The output your pipeline stage creates, such as that shown in the Sample Captured Data (.csv file) example above, can be imported into a Section Information Extractor stage.
Procedure:
- Successfully run your Section Headers Extractor pipeline stage,
- Disable your Section Headers Extractor pipeline stage in your list of pipeline stages.
- Enable your Section Information Extractor pipeline stage and click Apply.
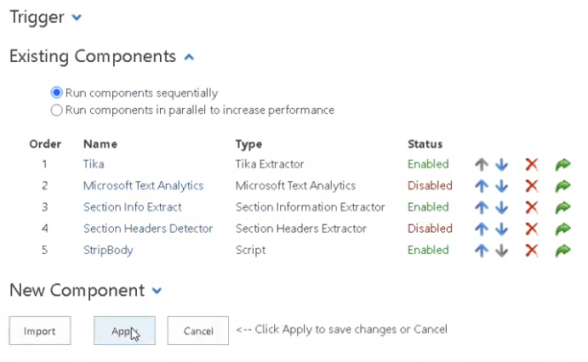
- Use "Choose File" to select your generated .csv file and click the Import from CSV button.
NOTE: The content from the .csv file overwrites ALL existing entries in the Section Patterns table.
Also, it is recommended to manually pre-process the CSV entries and only keep the section patterns you are interested in.
The CSV can be pretty large and not all the headers might be on interest.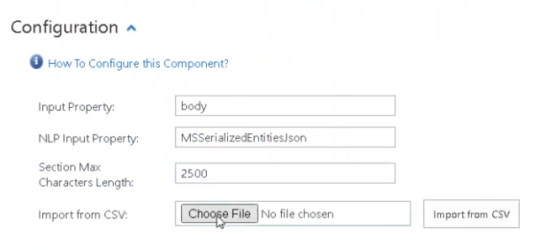
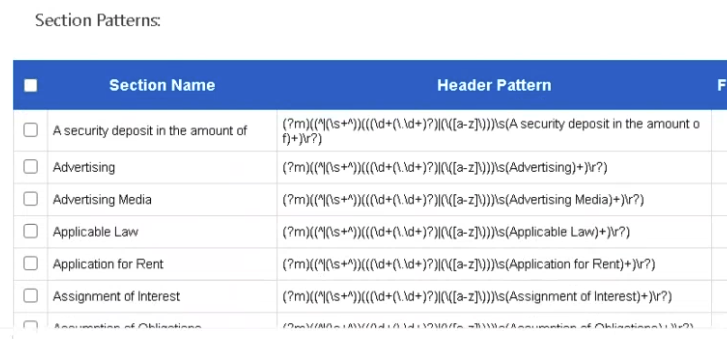
- The new content is imported and sorted alphabetically (shown below). No NLP data is provided.
- Click Apply.
- Test your newly configured pipeline stage using the Pipeline Testing stage described below.
Note: If you specify multiple section information header patterns, as shown above, each subsequent Header pattern indicates to AutoClassifier that the previous header-defined section ended and a new one has begun.
*Footer patterns are optional.
Detailed Section Headers Extraction
To extract even more detailed information from the document, add NLP data to the Section Patterns table.
-
You must specify the data you want to extract under "Output Property" as well as the respective "Type" of metadata for each property.
Property types, as shown in the example below under the "Type" column are pulled from the NLP service, such as Microsoft Azure or Google.
- Simply click the "+" icon under the table column "Add NLP Data" from the "Section Patterns" table.
- Click the Apply button when you are done.
See the example below, detailing the Properties:
- PhoneNumber
- LandlordAddress
Note: The PhoneNumber and Landlord Address properties in the table below will return the phone number and landlord address for ONLY the section "LandlordDetails" in the document, because the properties are entered on the same row as the Section Name "LandlordDetails".
