Microsoft Text Analytics Natural Language Processing (NLP)
This component analyzes text and extracts detected languages, entities, key phrases and sentiments.
This component uses the Microsoft Text Analytics API.
High Data Usage: Save Money by Using a Trigger
To help you avoid accidentally high cloud data costs, BA Insight designed a predefined "trigger" for the NLP component:
-
The trigger is enabled by default, in sample form.
-
The trigger provides sample code that includes the sources to process, (with sample values).
-
You must modify the trigger code according to your needs
Note: Not implementing this trigger can result in high data costs from your cloud data provider.
For example, when crawling 5 different content sources with a total of 1M items, a high number of documents processed for Natural Language extraction can generate high cloud data costs.
Use the following steps:
-
Add the desired component, normally.
-
When configuring the component, expand the Trigger section and adapt the predefined trigger to your needs.
-
Continue with component configuration.
The predefined (modify before using) script value:
//change the trigger script accordingly
//to the sources that you want this stage to process
//for the example below to work, ContentSource metadata must be
//available on the item to be processed; otherwise adapt your
//script to match your metadata and sources you want to process
var allowedContentSources = new List<string>() { "Source1", "Source2" };
string contentSource = item.Get<string>("ContentSource");
if (string.IsNullOrEmpty(contentSource) ||
!allowedContentSources.Contains(contentSource))
return false;
return true;The Components affected by this change are all the BA Insight components that make API requests to Microsoft:
-
Microsoft Text Analytics
-
Custom Vision AI
-
Image Processor MS Computer Vision
-
Video Processor Microsoft Video Indexer
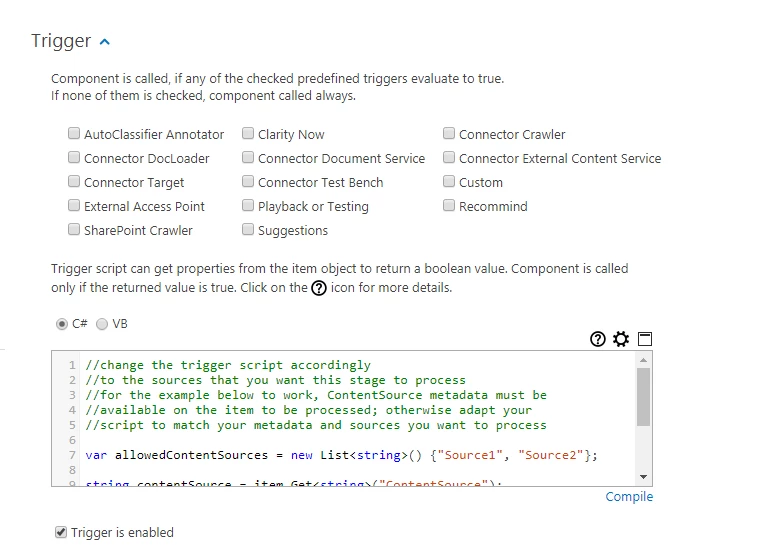
How to Trigger Your Pipelines Only for Video Files
The script below can be entered into the Trigger screen code window above.
This script runs only if the file extension detected is a supported video format.
-
Add to the script only the formats you truly wish to process.
-
Adding all the supported video file extensions is unnecessary and inefficient.
This aids you in reducing data usage, thereby saving money.
For more on using Pipeline Triggers, see Add Triggers to Determine When Your Pipelines Run.
// add here all allowed extensions, but always in lowercase
var allowedExtensions = new List<string>(){"mpeg4", "mp4", "avi"};
string fileext = item.Get<string>("escbase_fileextension");
if(fileext!=null)
{
if(allowedExtensions.Contains(fileext.ToLower()))
return true;
}
return false;How to Configure the Microsoft Text Analytics Component
To configure this component, use the following image and steps:
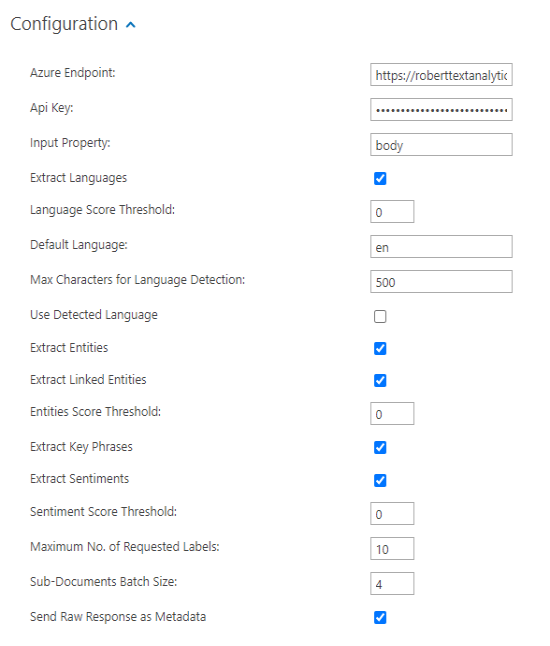
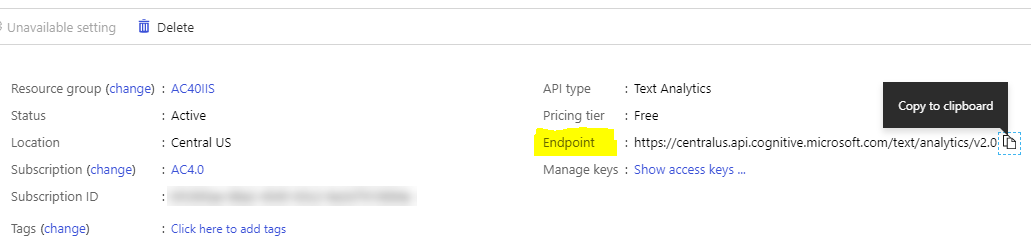
- Azure Endpoint: The Base of the Azure Endpoint of your Text Analytics Cognitive Service. For example: https://centralus.api.cognitive.microsoft.com.
- Api Key: Setup your Microsoft Azure Account, obtain an API key, and enter your key into this field.
- Input Property: Property configured for entity extraction. Default value: 'body'
- Extract Languages: Click to extract and output the languages that are detected in the current document.
- Language score threshold: Specify a value between 0 and 1 that represents the minimum confidence score accepted for a detected language.
- Default Language: Specify the predefined language that is used to analyze the text in case no other detected language is found.
- Max Characters for Language Detection:Specify number characters (first X characters from each document) that will be used for document language detection. By using this threshold, you execute less requests to Microsoft Azure Cloud service , you reduce costs and improve performance.
- Use detected language: Click to use the detected language with the highest confidence to analyze the text for entities, key phrases, or sentiments.
- Extract entities: Click to detect entities in the input text.
- Extract Linked Entities: Click to detect linked entities in the input text
- Entities “No. of Matches” threshold: Specify the minimum number of occurrences for a given entity to be included in the output results.
- Extract key phrases: Click to detect key phrases in the input text.
- Extract sentiments: Click to analyze the input text to determine whether it contains negative or a positive content.
- The sentiment value has a value between 0 and 1.
- 0.5 is neutral sentiment.
- Enabling sentiment extraction will also enable sentence extraction
- Sentiment score threshold: Specify the minimum number to determine if an overall document has a positive or negative sentiment.
- A score above the threshold flags the
MicrosoftPositiveSentimentDetectedproperty as true. - A score below the threshold flags the property as false.
- A score above the threshold flags the
- Maximum No. of requested labels: Specify the maximum number of distinct entities to return per item property.
- Sub-documents batch size: Processing of one big document is done in batches of documents under 5K characters. Specify the number of such sub-documents to be processed at once. Recommended maximum 5.
- Send raw response as metadata: Click to attach the JSON file response from Microsoft Text Analytics to the list of output properties.
Input Properties
File RawData- (Optional) The property specified in the Additional input property configuration option.
Output Properties
|
Property |
Type |
|---|---|
|
MicrosoftExtractedLanguages |
Text – Multi |
|
MicrosoftExtractedEntities |
Text – Multi |
| MicrosoftExtractedEntitiesLinks |
Text – Multi |
| MicrosoftExtractedPhrases | Text – Multi |
| MicrosoftExtractedSentiments | Boolean |
| MicrosoftPositiveSentimentDetected | Boolean |
| MicrosoftExtractedSentimentScore | Double |
| MicrosoftExtractedSentences* | Text - Multi |
| MicrosoftRawResponse | Text |
| MSSerializedEntitiesJson | Text |
Note: *MicrosoftExtractedSentences metadata property will only be returned if Extract Sentiments is set to True