How to Extract HTML Text and Metadata from Documents
To extract HTML text and metadata from documents in your source system such as PDF or MS Office documents, first install and configure the Tika Text Extraction Service.
-
Components such as the Azure Cognitive Search Service or BA Insight Connectors use the Tika Text Extraction service to crawl HTML pages to correctly index documents such as MS Office or PDF documents.
-
Extracted information can then be consumed by BA Insight Connectivity Hub or Connector Framework.
Extracted information includes:
- Available text and metadata which can be mapped to metadata properties.
- HTML metadata tags from HTML pages.
- Available HTML tags and links for use as metadata from HTML documents
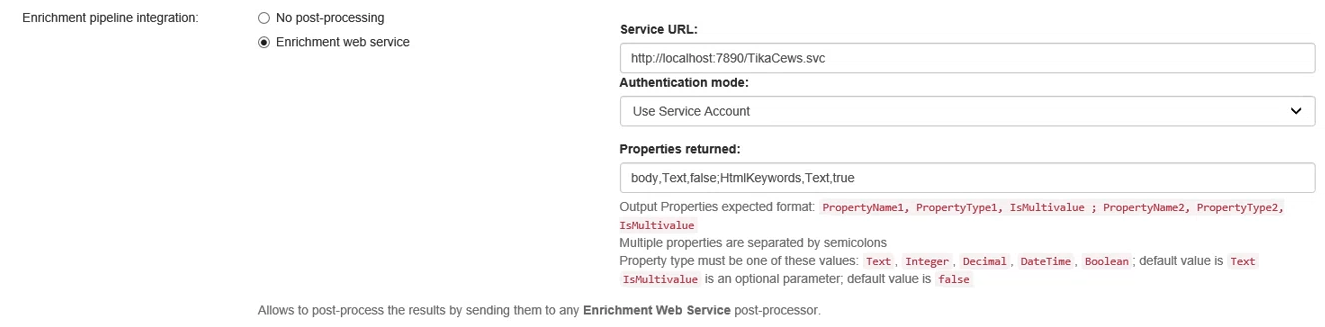
Before Connectivity Hub or Connector Framework can consume the extracted information, set your connector framework, in this case Connectivity Hub, to post-process using the Enrichment web service:
- Edit your web service connector.
- Select the "Advanced" tab.
- Select the Enrichment web service radio button at the bottom of the page.
- Enter the following (see the screenshot below for examples):
- Service URL
- URL of your enrichment service
- Authentication mode
- Select the mode used to authenticate
- Set to Use Service Account, by default
- Properties Returned
- Enter the property type and format as specified in the instructions under the field
- Service URL
Tika Text Extraction Example