How to Install the Tika Text Extraction Service
About
The Tika Text Extraction service is used by components such as the Azure Cognitive Search Service or BA Insight Connectors to crawl HTML pages to correctly index documents such as MS Office or PDF documents.
For example, the following BA Insight Connectors extract (crawl) HTML pages:
- Website
- ServiceNow
- SharePoint
- other connectors
Extracted information can then be consumed by Connectivity Hub or Connector Framework.
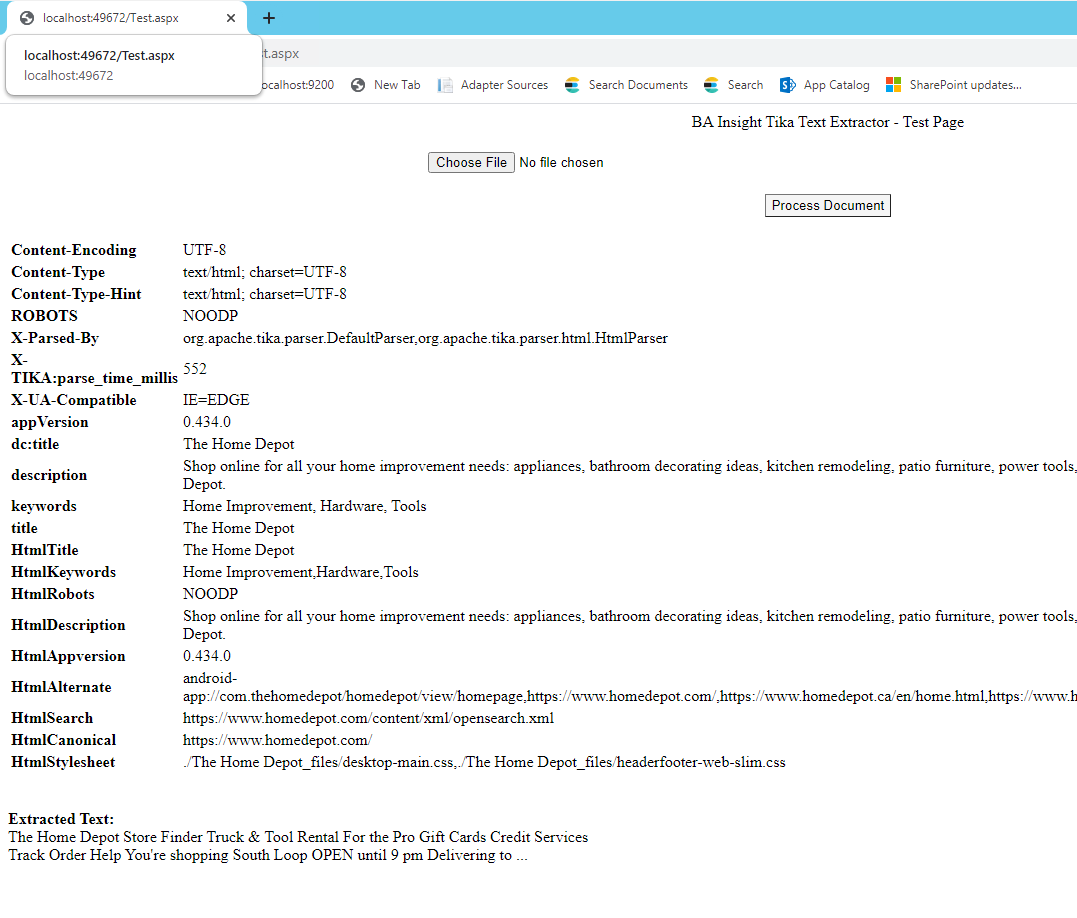
To see an example of extracted HTML metadata, see the screenshot "Test Page Providing Available HTML Metadata" below.
The service is offered natively as a component of AutoClassifier.
The Tika Text Extraction service:
- Extracts available text and metadata which can be mapped to metadata properties.
- Extracts HTML metadata tags from HTML pages.
- Extracts available HTML tags and links for use as metadata from HTML documents.
Install the Text Extraction Service
The Tika Text Extraction service is installed as a service, separate from any other BA Insight program.
You must download the service in the form of a .zip file from the Upland Support Portal and install it on the same server as BA Insight Connectivity Hub.
Follow the instructions listed here:
- Install Java Runtime Environment (JRE) v8 LTS on your server.
- Download the Tika CEWS Service package from Upland Right Answers Portal (direct link).
- Unblock the downloaded .zip file.
- Extract the contents of the .zip file.
- Run the .MSI file found in the downloaded package.
Configure the Text Extraction Service
- Run C:\Program Files\Apache Tika Server\register.bat to create the Tika Service
- On first tab, Application), enter the following:
- java.exe in the Path text field:
- C:\Program Files\Apache Tika Server in the startup directory text field
- -jar "C:\Program Files\Apache Tika Server\tika-server-1.16.jar"in the arguments field
- On Log On tab set the account to run the Tika service
- Ensure the account specified has full permissions on the folder C:\Program Files\Apache Tika Server\Logs folder.
- Ensure the account specified has full permissions on the folder C:\Program Files\Apache Tika Server\Logs folder.
- On I/O tab redirect both
stdoutandstderrto the path C:\Program Files\Apache Tika Server\Logs\TikaServer.log.
- On the File Rotation tab, configure a time or size based log file rotation:

- java.exe in the Path text field:
- On first tab, Application), enter the following:
- Click the Install Service button.
- Find the Tika Server service in the list of Windows services, and start it.
- The Tika Server is now running on port 9998
- the Tika Text Extraction service is running on port 7890.
- To test the service, navigate to the service URL: http://localhost:7890/Test.aspx.
- Click browse, and select a text file (.txt).
- Click the Process Document button to see the extracted text metadata.
- The test page can be used to determine available metadata for processing.
- Metadata and/or body text can be consumed by Connectivity Hub.
Test Page Providing Available HTML Metadata
Configure Post-Processing: Enrichment Pipeline Integration
Once the Tika Text Extraction Service is installed, your final step is to configure post-processing in Connectivity Hub.
To do this, configure the Enrichment Web Service as described here: How to Extract HTML Text and Metadata from Documents.