How to Use Learn-To-Rank Features
Important Mentions and other Limitations
-
Learn-To-Rank works only with SmartAnalytics v5.0 or above.
-
The Learn-To-Rank features do not work with a NetDocuments backend The search engine your SmartHub instance uses to perform queries. SmartHub can be configured to use more than one search engine..
-
When upgrading SmartHub the file BAInsight.LearnToRank.Trainer.exe.config is overwritten.
-
Back up the settings and manually re-add them after the upgrade.
About Learn-To-Rank
The Learn-To-Rank component is implemented on top of SmartAnalytics data to support three main features:
- Results Boosting
- Query suggestions
- Content suggestions
Learn-to-Rank uses clustering algorithms (K-means, but extendable to any other algorithm) to build clusters of similar (related) queries and their associated “important” documents.
- Learn-To-Rank groups queries and documents based on query similarity as well as user interaction with documents after a query is executed.
- These groups are called "clusters".
In a cluster, there are:
- Queries that are similar on the containing keywords
- Documents that those queries led to
- Other queries that are not necessarily similar in keywords, but led to the same documents as other queries
Learn-To-Rank Page
The Learn-To-Rank page can be found in the SmartHub Administration page (https://<hostname>:port/_admin), in the left panel.
The page is composed of two parts:
- Features Configuration
- Training Results (data)
Features Configuration
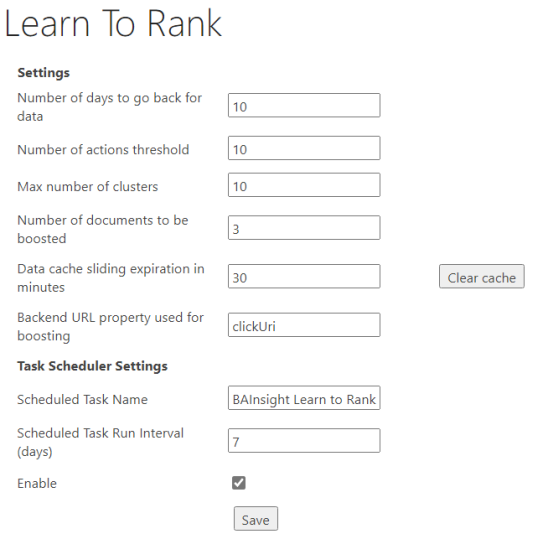
Below you see the Learn-To-Rank settings as they appear in the SmartHub interface.
See the section "Training Results" below for more details and examples of the settings shown here.
- These settings must be fine tuned, over time, to fit properly with your environment and data
- Properly tuned settings reveal the most relevant documents within a cluster and search query
| Setting | Default | Description |
|---|---|---|
| Learn to Rank Index Name | learntorank-cluster-storage |
Learn To Rank index name to be used for cluster storage Note: In case that the name of the index is changed, after an index is already created, the old index will not be removed from Elastic. |
| Number of days to go back for data | 30000 | Total number of days for query analytics data freshness. |
| Number of actions threshold | 20 |
The minimum number of executed queries in order to be used for training. This number must fit your environment.
|
| Max number of clusters | 10 |
Total number of clusters that you want your data to be split into. This number must fit your environment.
|
| Number of documents to be boosted | 2 |
|
| Data cache sliding expiration in minutes | 30 minutes | Sliding expiration of data to be stored in cache. |
| Backend URL property used for boosting | clickUri | The property that your backend uses for path. |
| Clear cache | N/A | Clear cache for the existing clusters |
| Scheduled Task Name | BAInsight Learn to Rank Scheduler | The name of the scheduled task used to run the LTR trainer |
| Scheduled Task Run Interval | 7 |
|
| Enable | true | This should be set to true in case that you want to automatically train the data |
Learn-To-Rank Trainer
The trainer takes the data from SmartAnalytics and creates the clusters (shown in the screenshot in section "Training Results" below).
- The trainer is in the SmartHub package /Scheduled Jobs/LearnToRank/Trainer.
- If you change the paths for the logger configuration file folder - /config/caching - you have to change it in the trainer as well.

- If the installation is successful, a new scheduled task is created in Windows Task Scheduler.
- The name of the task is the one specified in the Scheduled Task Name field from the Learn-To-Rank page.
Training Results
Note: Clusters might contain documents that are deleted in the search index.
-
This is because the Analytics index still contains them.
-
In time they disappear from this list as usage for other documents increases.
-
If you want to accelerate the process you can manually delete them from the Analytics index and retrain the data.
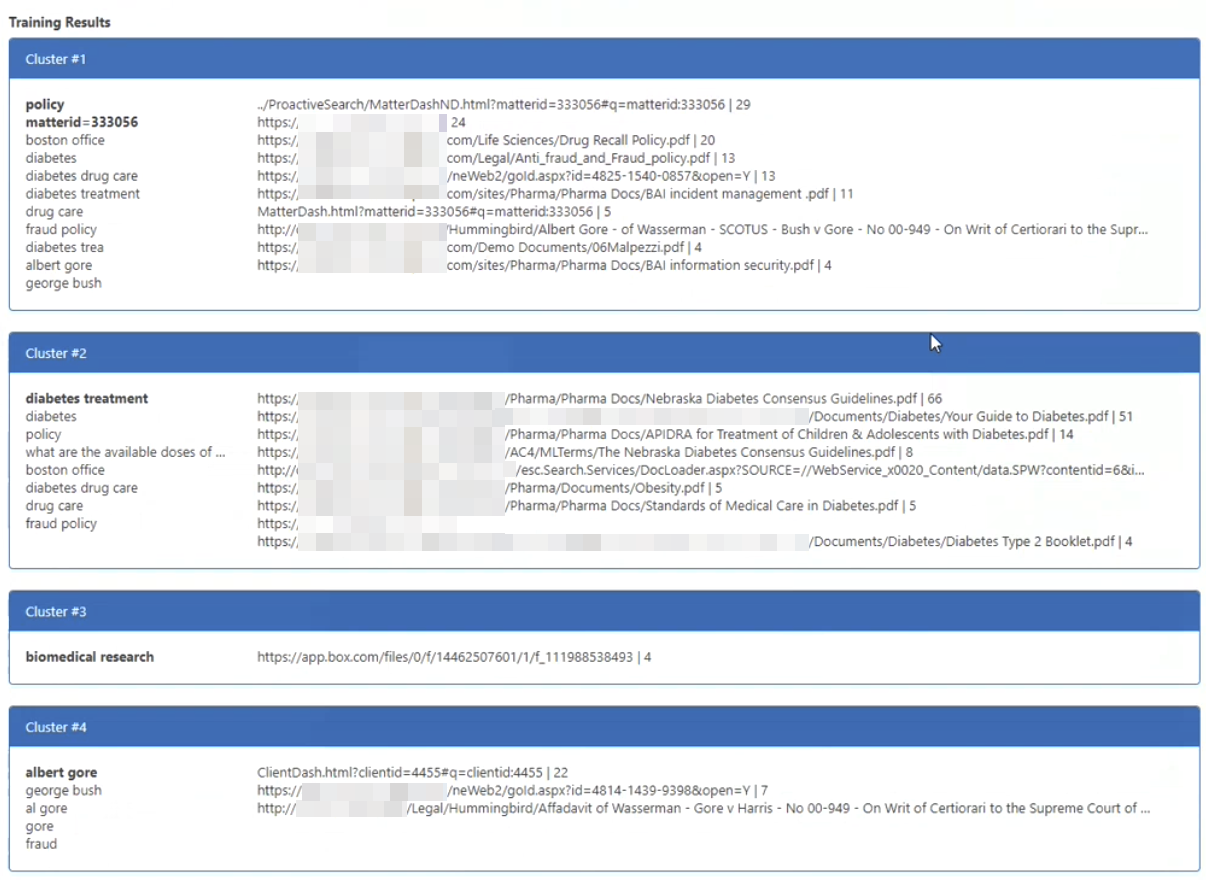
Sample Training results are shown below.
- Clusters - #1, #2, #3, #4
- Each cluster consists of:
- A series of queries, shown on the left
- Document URLs for each query listed on the right
- Number of actions taken on document on far right (download, opening, previewing, etc.)
- Queries, based on their keywords similarity, are grouped into clusters
- Each cluster consists of:
- Bold text - policy matterid=333056, diabetes treatment, biomedical research, albert gore
- Original cluster query
- The documents this query led to (and a specific threshold number of actions were taken to those documents) are added to the cluster
- The number of actions threshold is set in the table above in Number of actions threshold.
- This is set to a very low value of 4 due to the small data set in this sample.

- This is set to a very low value of 4 due to the small data set in this sample.
- The number of actions threshold is set in the table above in Number of actions threshold.
- For example, in Cluster #1, the query text policy matterid=333056 led to the documents shown in Cluster #1 below, "Drug Recall Policy.pdf," "Anti_fraud_and_Fraud_policy.pdf," etc.
- Note: Production environments will most likely have a document threshold in the thousands.
- Plain text queries
- Plain text, unbolded queries on left, under the bold text query, are queries that are pulled or "inherited" based on the document list on the right side
- These are the top queries which users have run to discover and take action on the documents listed on the right.
- In other words, a "backwards looking" query on the documents shown yields these queries, listed on the bold, original cluster query
Features
Learn-To-Rank Boosting
During a search, this stage checks if the query matches any of the clusters.
-
If the query matches a cluster it boosts the documents in that cluster according to their hits (number of clicks, previews, etc.).
-
The documents that are selected to be boosted are documents that the current query (or very similar query) lead to.
-
The boost value is proportional with the number of actions of each document that the current query lead to and is within a the 1 - 100 range.
- To use Learn-to-Rank Results Boosting:
- Create a stage with empty parameters.
- The stage must be first stage in the list of stages in the section "Query Pipeline Stages"
Learn-To-Rank Query Suggestions
This feature provides suggestions as query text is entered in the search field.
The Learn-To-Rank Query Suggestions provider is located under TypeAhead.
To enable and use this TypeAhead provider:
- Add the following line in your custom settings file (from the folder "CustomSettingsTemplate") under the section SH.TypeAhead.CustomSettingsActiveProviders:
LearnToRankSuggestions: "/modules/TypeAhead/Providers/LearnToRankSuggestions/LearnToRankSuggestions.js"Example:
ActiveProviders: {
FederatorSuggestions: "/modules/TypeAhead/Providers/FederatorSuggestions/FederatorSuggestions.js",
PeopleSuggestions: "/modules/TypeAhead/Providers/PeopleSuggestions/PeopleSuggestions.js",
QuerySuggestions: "/modules/TypeAhead/Providers/QuerySuggestions/QuerySuggestions.js",
RefinerSuggestions: "/modules/TypeAhead/Providers/RefinerSuggestions/RefinerSuggestions.js",
SavedQueriesSuggestions: "/modules/TypeAhead/Providers/SavedQueriesSuggestions/SavedQueriesSuggestions.js",
LearnToRankSuggestions: "/modules/TypeAhead/Providers/LearnToRankSuggestions/LearnToRankSuggestions.js"
},Settings
Learn-To-Rank Content Suggestions
This feature provides the user with similar (search) results, excluding those present on the current page.
Learn-To-Rank Query Suggestions settings are shown in the screenshot below.
These similar search results are derived from the Content-By-Search module.
This is also used in the component Similar Documents.
-
For more about Content-By-Search, see How Users Can Personalize Their Search Results.
- Learn-To-Rank Results Suggestions Pipeline Stage Pipeline stages offer uniformity to the end user. Various functions include mapping names and values to match local refinements.
- In order to use Learn-to-Rank Results Suggestion, create a stage with empty Parameters.
- The stage must be first in the list of stages under Query Pipeline Stages section seen in the SmartHub Administration UI.
- The Learn-To-Rank Similar Results module is located under <SmartHub installation>/modules/LearnToRank.
- In this module a Learn-To-Rank settings file contains the ID of your Content-By-Search (Learn-To-Rank element) and the URL property.
- This ID can be modified.

Note: Be aware of the relevancy stages order!
Learn-To-Rank works only with SmartAnalytics v5.0 or above.