Adding AI Search capabilities to your Azure AI Search content
This section is only applicable if vector fields and document chunking are required in order to leverage Microsoft Azure AI Vector Search capabilities. If you plan to use vector fields and document chunking in your index, you must satisfy the following prerequisites and note any limitations.
Using AutoClassifier components to enhance metadata
BA Insight AutoClassifier allows you to enhance the metadata of your indexed content with specific functionality. Refer to the following to see how you can implement AutoClassifier functionality in Connectivity Hub:
-
Connect Connectivity Hub to AutoClassifier to generate vector embeddings using scripts
-
Connect Connectivity Hub to AutoClassifier to index document chunks
Additionally, you can apply vector embeddings to your document chunks by configuring both of these components in your AutoClassifier pipelines. For more information, see Generate vector embeddings for chunked content in the AutoClassifier documentation.
For more information, see How to Integrate AutoClassifier with Connectivity Hub or Connector Framework.
Connect Connectivity Hub to AutoClassifier to generate vector embeddings using scripts
Refer to How to Generate Vector Embeddings via Scripting in the AutoClassifier documentation and ensure that you have configured the component.
Prerequisites
-
The Azure index that will contain vector fields must be manually created before indexing, using the 2023-10-01-Preview API version.
Currently, the Azure portal is facing some when creating vector fields in an index. Therefore, you should use the workaround described in the Create a Microsoft Azure index section to create an index and vector field. -
Vector fields must be created and configured in Microsoft Azure before you try to populate them with Connectivity Hub.
-
To create and configure vector search configurations and vector fields, you can follow the steps in the Microsoft documentation for Add a vector search configuration.
-
-
If you want to return a vector field as metadata on the results page, you need to specify that the vector field is retrievable when creating it in Microsoft Azure.
-
The AutoClassifier Engine must be installed and configured.
Limitations
-
Upgrading an existing Microsoft Azure index to support vector fields is currently not supported. Vector fields will only work with newly created indexes.
Procedure
To populate vector fields into the Azure index when running Connectivity Hub tasks, do the following:
-
Create a Microsoft Azure index with your desired schema for vector fields.
-
In Connectivity Hub, navigate to the Content Sources page.
-
Create a content source with the same name as the Azure index that uses the Microsoft Azure target.
-
Configure AutoClassifier to generate vector embeddings via scripting.
-
Configure the enrichment pipeline integration on the content source.
-
Delete the automatically created metadata that corresponds to the Output properties that were configured on the Microsoft Azure content source in step 5.
Output properties have the following format:ESC_<OutputPropertyName>. You will have to manually delete the automatically created meta data properties each time you generate them.
Configure the enrichment pipeline integration on the content source
-
In Connectivity Hub, navigate to the Content Sources page.
-
Edit the content source that corresponds to your Microsoft Azure index.
-
Select the Advanced tab.
-
Scroll down to the Enrichment pipeline integration section.
-
Select the Enrichment web API option and specify the following:
-
Service URL: Enter the URL of the enrichment web service.
-
Authentication Mode: Select your authentication mode from the drop-down list.
-
Properties returned: Provide a list with the output properties in the following format: PropertyName,PropertyType,IsMultiValue. You must use a semicolon to separate list items.
-
PropertyName: The name of the property that was set in the AutoClassifier pipeline stage.
-
PropertyType: Decimal
-
IsMultiValue: true
-
Create vector metadata in Connectivity Hub
-
In Connectivity Hub, navigate to the Content Sources page.
-
Click the Actions button for the content source that corresponds to your Microsoft Azure index and select Metadata.
-
On the Metadata page, click New.
-
From the drop-down list, select Numeric metadata.
-
In the modal window, provide the details for the following fields:
- Title: Enter the name of the vector field. The name is case-sensitive and must be the same as the one that you configured in the Microsoft Azure index schema.
- Description: Enter a short description of the vector field.
- Value:
Select The value is calculated by an enrichment pipeline.
From the drop-down list, select your property.
- Active: Checked
- Searchable: Unchecked
- Full text index: Unchecked
- Multiple values: Checked
Since Microsoft Azure does not support changing existing fields, you will need to run a Target Content Reset task each time you change your vector metadata. The vector metadata must only be active and support multiple values.
-
Click Save.
Validate the implementation
To validate your implementation, you can do one of the following:
-
Run a Test Bench and validate that your vector field contains an array of float numbers. Verify that the dimension of the array matches the dimension of the vector field
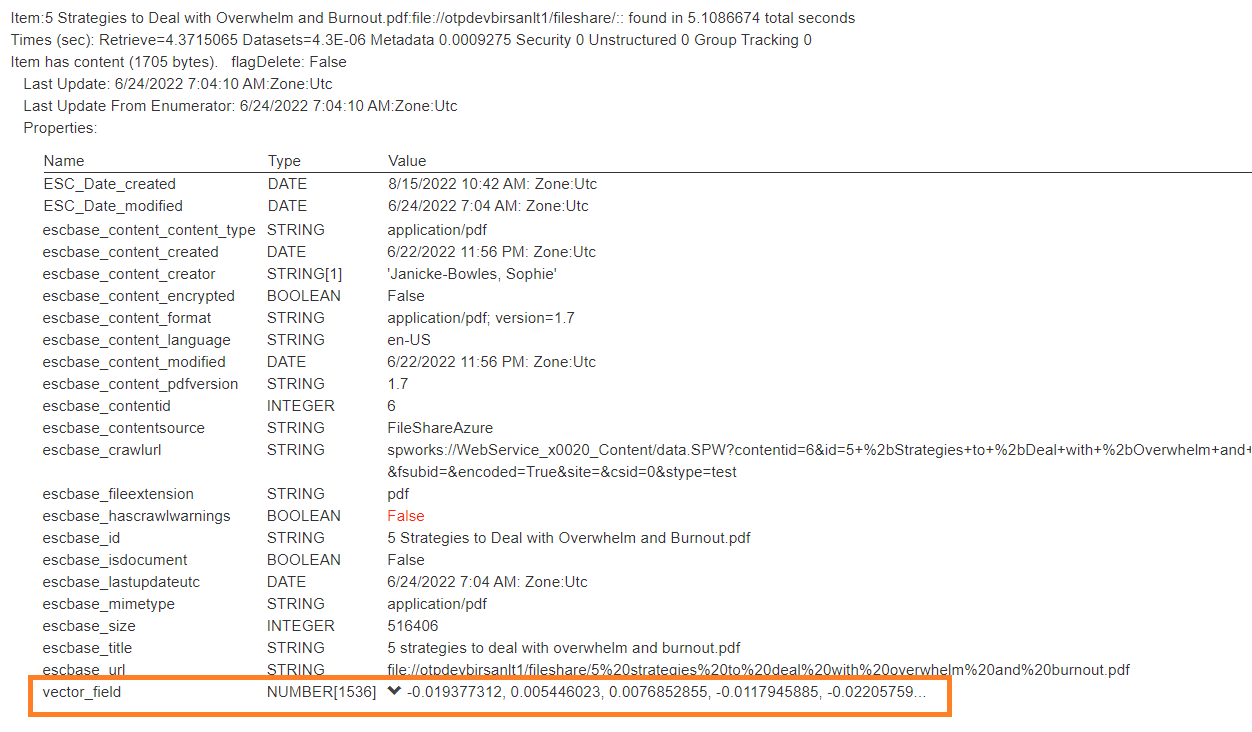
-
In the Microsoft Azure portal, verify that the vector field is populated in the index.

Connect Connectivity Hub to AutoClassifier to index document chunks
In AutoClassifier, you can use the Document Chunker component to break a document into smaller, more manageable segments, in order to surface search results that are more accurate and relevant to the user search query. For more information, see Configure the document chunker component in the AutoClassifier documentation.
Configure the enrichment pipeline integration on the content source
-
In Connectivity Hub, navigate to the Content Sources page.
-
Edit the content source that corresponds to your Microsoft Azure index.
-
Select the Advanced tab.
-
Scroll down to the Enrichment pipeline integration section.
Select the Enrichment web API option and specify the following:
-
Service URL: Enter the URL of the enrichment API endpoint.
-
Authentication Mode: Select your authentication mode from the drop-down list.
-
Properties returned: Provide a list with the output properties in the following format: PropertyName,PropertyType,IsMultiValue. You must use a semicolon to separate list items.
-
PropertyName: The name of the chunk body property that was set in the AutoClassifier Document Chunker stage.
-
PropertyType: Text
-
IsMultiValue: False
-
Validate the implementation
To validate your implementation, you can do one of the following:
-
Run a Test Bench on the content source and validate that you can see the number of child items. This appears as in the Name column with the text "Item has x child items.". You can click on this text to expand each child item to view the property that you specified in the PropertyName field when you configured your enrichment pipeline and any additional properties that you specified in a script (see Alter chunks with a script component). Test Bench will show the top 10 child items if more than 10 child items exist.
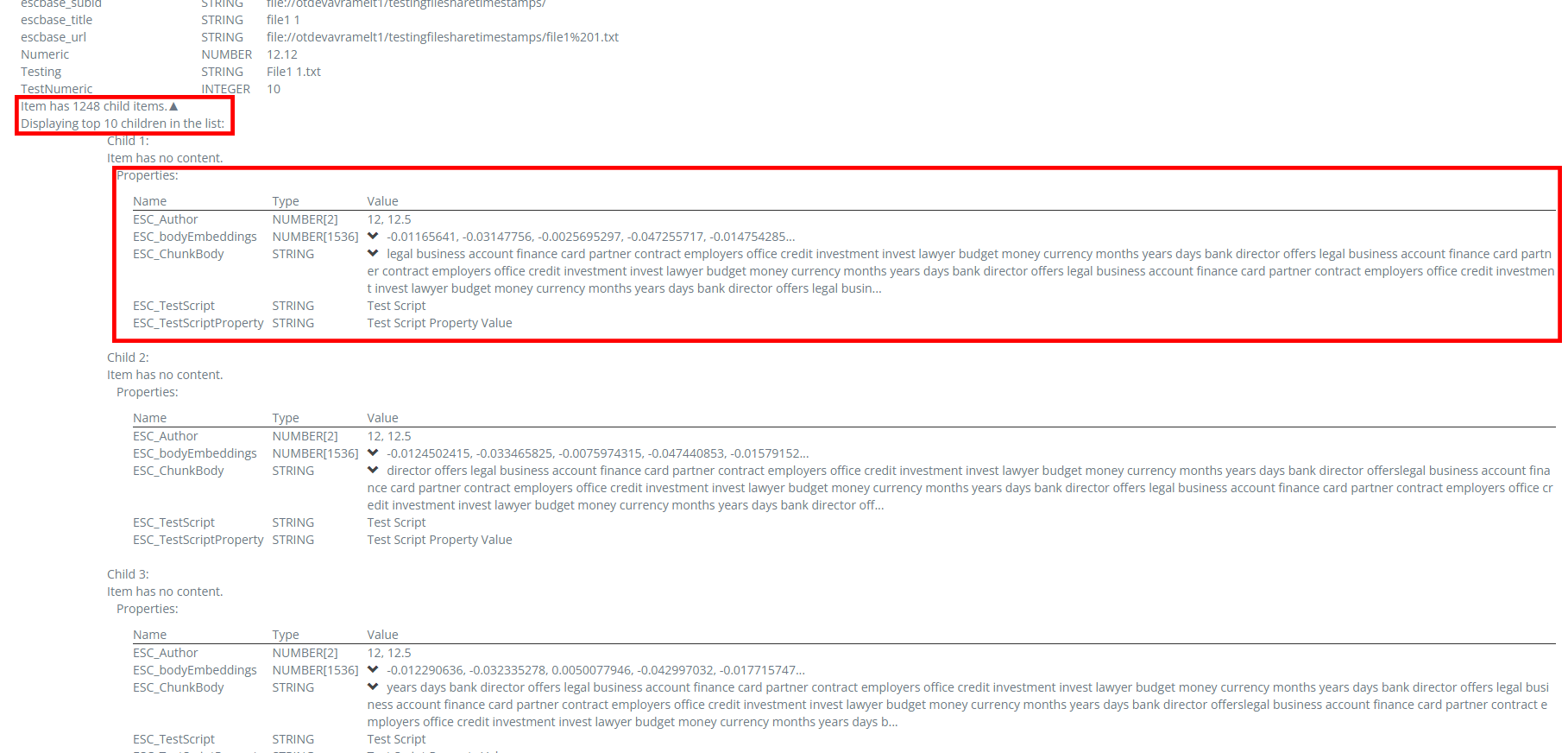
-
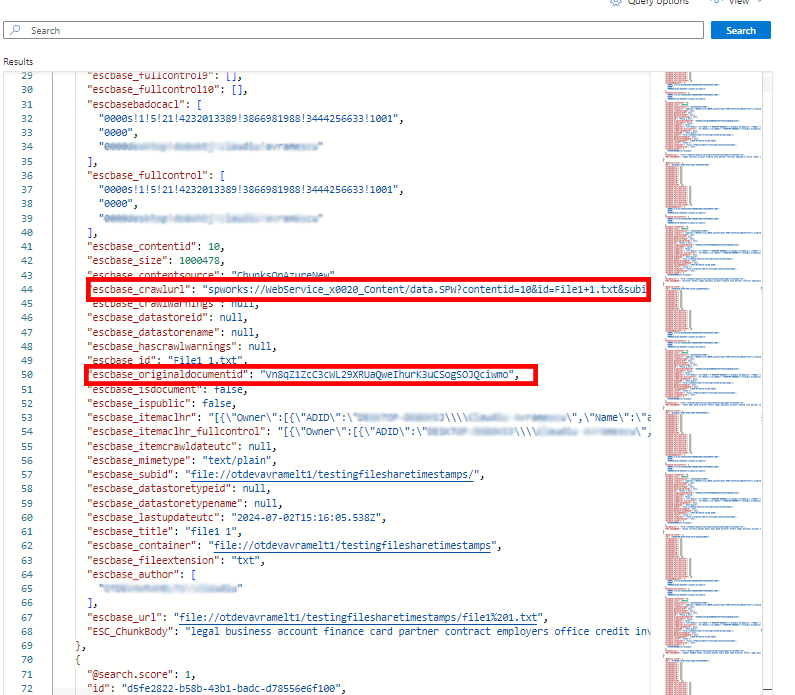
In the Microsoft Azure portal, verify that the properties that you specified in the PropertyName field when you configured your enrichment pipeline are present. Additionally, you can verify that the following properties maintain information about the parent document:
-
escbase_crawlurl: This is the url to the parent document.
-
escbase_originaldocumentid: This is the document id of the parent document.
-