Adaptive Extraction stencil
The Adaptive Extraction stencil is used to automatically extract information from documents using a machine AI learning model. When this stencil is used, the document does not have to go through OCR or be trained.
Note: The machine AI learning model has a practical output limit of around 2,500 words after system overhead. If results from a document exceed this size, information appearing after the limit will be truncated and excluded from the return.
The stencil uses your Data Dictionary to understand what to extract and how to interpret it. Each data field entry contributes specific signals to the AI:
|
Attribute |
Purpose |
|---|---|
| Name and Description | Defines what to look for (e.g., “Invoice Number,” “Total Amount,” or “Document Type”). |
| Type | Tells the model how to interpret the value. For example, Date, Currency, Decimal, Text, or List. |
| Description | Provides extra context that influences the AI’s query and
extraction accuracy. Descriptions are especially powerful for abstract fields
such as summaries or classifications. The Description field can dramatically improve the quality and precision of AI extraction. For instance: • A field called Total with the description “Total amount due including tax and discounts” helps the model differentiate it from subtotals or line-item amounts. • A Document Summary with a description like “A 20–30 word summary of the document’s contents” guides the AI to produce structured, concise text rather than a full paragraph. Tip: When a field isn’t being found correctly, refine its description to give the model more context. |
After going through the Adaptive Extraction stencil, each data field will be highlighted on the document as follows:
-
Green = 80% or higher confidence
-
Yellow = 50% - 80% confidence
-
Red = under 50% confidence
All extracted data fields will be available on the Journal tab in Document Properties. See View document properties for more information.
Note: Each document that is processed through this workflow stencil will decrement your page count license by the number of pages displayed.
Example use cases
Document Type (List Data Type)
If Document Type is configured as a List containing items such as Invoice, PO, and Packing Slip, the stencil will:
• Scan the document’s contents.
• Match language patterns and layout to known list values.
• Automatically select the most relevant type.
This allows for easy document categorization without manual input.
Document Summary (Large Text Data Type)
A field such as Document Summary can be defined to generate a concise overview of the document’s contents.
• Type: Text
• Description: “Provide a 20–30 word summary describing the main contents and purpose of the document.”
When used, the AI model will return a short natural-language summary — ideal for quick previews, reporting, or downstream automation.
Available connections
There are four outgoing connections from a Adaptive Extraction stencil:
- Success: All Found: The data extraction was successful and the model believes all data was found.
- Success: Some Found: The data extraction was successful, but the model didn't find all of the data.
- Success: None Found: The data extraction was successful, but the model didn't find any data.
- Failed: An unexpected error occurred preventing the extraction process from completing on the document.
Configuration
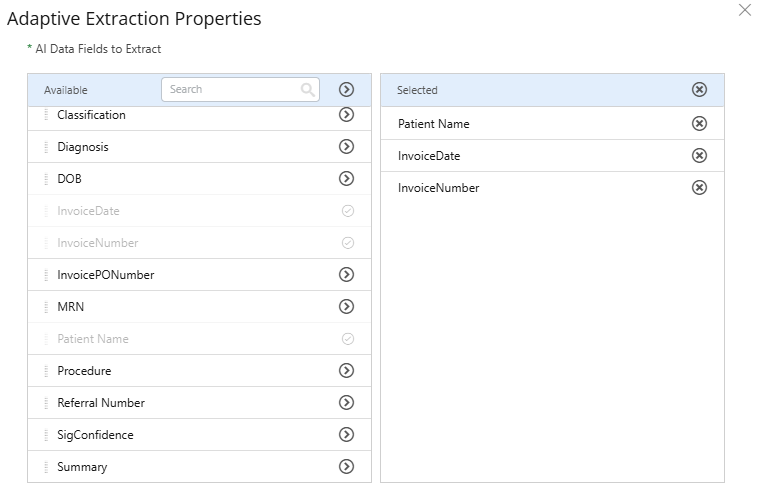
- To access stencil properties, double-click an Adaptive Extraction stencil. Or, right-click an Adaptive Extraction stencil and select Properties.
-
Click Add (>) next to the data field(s) you want to extract from the document. Or, move data fields from the Available box to the Selected box using a drag-and-drop operation.
To remove a data field, click Remove (X) next to the data field in the Selected box.
- Click Save.