Structured JSON Data
This is the second topic of the Simple Data Lookups guide.
Working with tabular data is common, but when the dataset requires hierarchical relationships, nested elements, or more complex configuration structures, a JSON-based format is typically more appropriate. Much of this approach is similar to working with tabular data.
JSON allows structured grouping of related properties, for example, document-level settings combined with brand-specific stationery definitions. The trade-off is that the maintainer must ensure the structure remains valid JSON, as syntax errors will prevent the configuration from loading.
Below is an example of a nested JSON configuration. The top-level entries are keyed by document type (inv, stmt), which enables direct key-based lookups in both JSONata and JavaScript. Within each document type, additional nested structures define brand-specific stationery settings.
{
"inv": {
"name": "invoice",
"orientation": "portrait",
"groupByAddress": true,
"maxSheetLogic": true,
"stationery": {
"brands": {
"abc": {
"letterhead": "invoice_letterhead_a",
"continuation": "invoice_continuation_a"
},
"xyz": {
"letterhead": "invoice_letterhead_x_v2",
"continuation": "invoice_continuation_x_v2"
}
}
},
"outputPreset": "invoice_print.OL-outputpreset"
},
"stmt": {
"name": "statement",
"orientation": "portrait",
"groupByAddress": false,
"maxSheetLogic": true,
"stationery": {
"brands": {
"abc": {
"letterhead": "invoice_letterhead_a",
"continuation": "invoice_continuation_a"
},
"xyz": {
"letterhead": "invoice_letterhead_x_v2",
"continuation": "invoice_continuation_x_v2"
}
}
},
"outputPreset": "invoice_print.OL-outputpreset"
}
}Data handling options
As with tablular CSV data, structured JSON sata can be handled in two primary ways:
Load from an external file
The dataset is read from a CSV or text file at runtime. This approach is appropriate when the data is maintained outside the flow, typically by business or operations users, or when updates occur frequently.
Embed in the flow
The dataset is defined directly in a Template node. In this case, the data becomes part of the flow definition and automatically travels with the flow when exported or deployed. This is suitable for small, static reference datasets such as lookup tables or configuration matrices.
The choice between loading an external file and embedding a file depends primarily on how often the data changes and who is responsible for maintaining it. Either approach can be used in the flows below. A flow that makes frequent calls to load external data from disk may operate slowly. Embedded data is generally more efficient, unless it frequently changes.
Data inline with the flow (message-scoped)

This approach is appropriate when only a single flow requires access to the configuration data. The dataset can either be:
-
Loaded from disk using a read file node.
-
Embedded directly in the flow using a template node.
Reading from disk ensures the latest version of the file is used, but it introduces runtime overhead because the file is read and parsed for every message. For small datasets, this is typically acceptable. A more efficient pattern, loading once at startup and storing in a flow variable, is covered separately.
When loading JSON data from disk, the Read File node must be followed by a JSON node. The Read File node outputs a JSON-formatted string, which needs to be converted into a native JavaScript object. This conversion is necessary because the application operates on JSON objects, allowing JSONata expressions and JavaScript logic to interact with the data correctly.
In this section, the configuration is recreated per message and remains scoped to this flow.
Flow nodes
-
The inject node triggers the flow with a dummy file name in
msg.payload.-
In production, this would typically be a folder capture node.
-
Example payload:
inv_net30_acc67829_20250001.xml
-
-
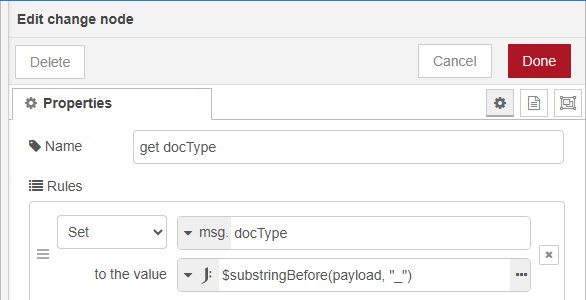
The change node extracts the lookup key (document type prefix) from the filename.
-
Configure the node Properties Rules to set the lookup key as
msg.docType -
Enter the JSONata expression value to
$substringBefore(payload, "_")
-
-
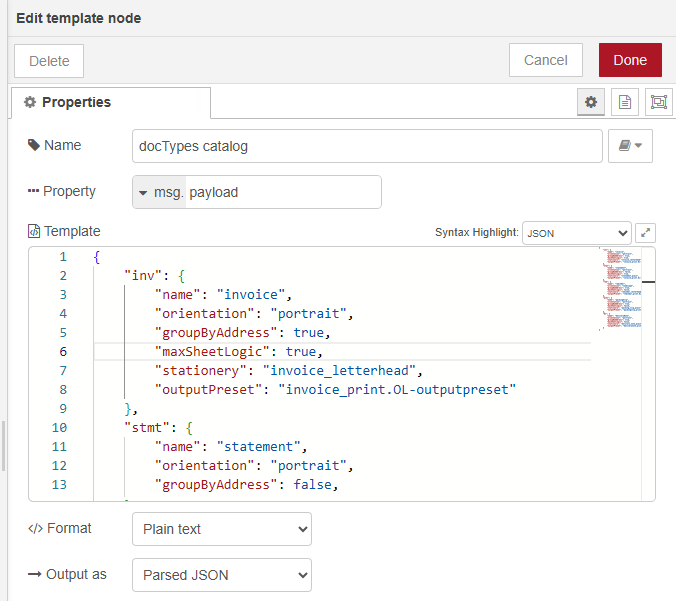
The template node stores the document type configuration as parsed JSON in
msg.payload.
-
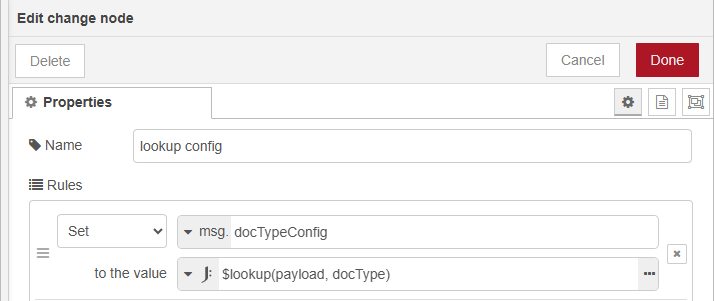
The change node performs the lookup using JSONata and stores the result in
msg.docTypeConfig.-
The value for the JSONata expression is:
$lookup(docTypes, docType)
-
Result
At this point, msg.docType contains the extracted document type and msg.docTypeConfig contains the matching configuration object.
Downstream nodes can now use this configuration to drive grouping logic, orientation, stationery selection, output preset selection, and other production parameters.
Data in a flow variable (shared configuration)
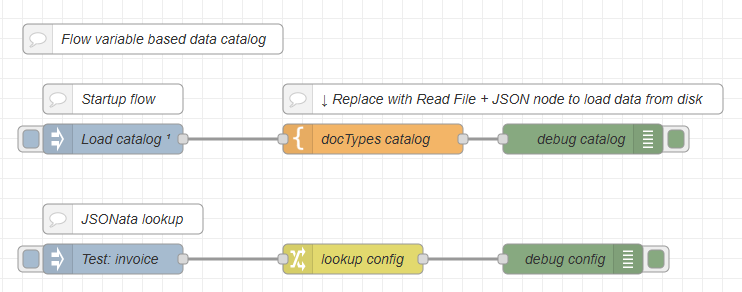
When multiple flows require access to the same configuration data, and when you want to clearly separate configuration loading from production logic, it is more efficient to centralize the loading process.
Instead of loading and parsing the dataset for every message, the configuration can be loaded once in a dedicated startup flow. This flow is responsible solely for reading, converting, and storing the reference data.
The configuration is then stored in a flow-scoped variable, making it available to all production flows on the canvas. This approach provides eliminates repeated file reads and parsing overhead, ensures a single source of truth and separates operational configuration from processing logic.
Flow overview
-
Flow 1: Inject (run on startup/deploy) > Template or Read File + JSON
-
Flow 2: Inject > Change or Function > …
Flow 1 - startup flow nodes
-
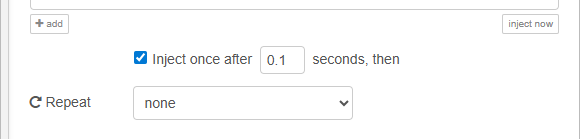
The inject node triggers the flow once after startup/deploy. This ensures the configuration is loaded before production traffic begins.
-
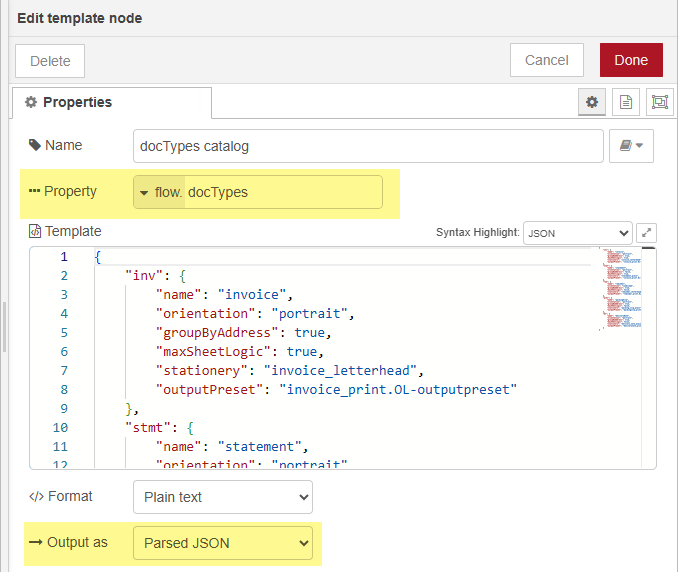
The template node stores the document type configuration as parsed JSON in a flow variable, for example
flow.docTypes.
Flow 2 - production flow nodes
-
The inject node triggers the flow with a dummy file name in
msg.payload. In production, this would typically be a folder capture node. Example payload:inv_net30_acc67829_20250001.xml
-
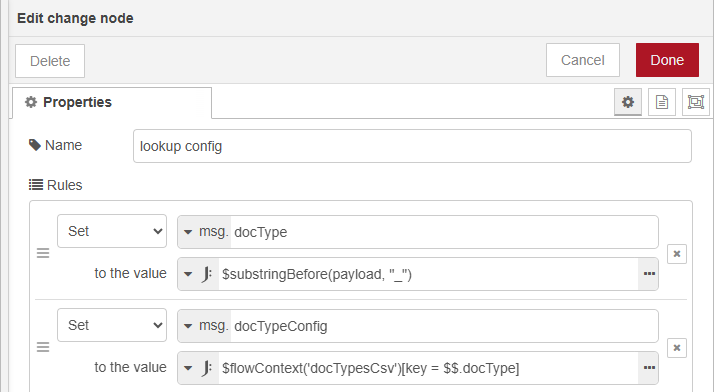
The change node extracts the lookup key (document type prefix) performs the lookup. The properties are configured with two rules:
-
Rule 1 extracts the document type from the file name, using a JSONata expression, and stores it in
msg.docType:$substringBefore(payload, "_") -
Rule 2 performs the lookup in
flow.docTypes, using the extracted document type with a JSONata expression, and stores the configuration inmsg.docTypeConfig.-
The JSONata expression is :
$flowContext('docTypes')[key = $$.docType])
-
-
Result
At this point, msg.docType contains the extracted document type and msg.docTypeConfig contains the configuration object. Downstream nodes can use these values for grouping logic, orientation, output preset selection, etc.
Storing configuration in a flow variable provides a clean architectural separation between configuration management and production processing. It avoids unnecessary duplication, supports multi-flow environments, and ensures predictable runtime behavior while remaining simple and low-tech.
The next topic is Lookup using JavaScript.